Recommendation engines have gained immense importance in today’s digital landscape. As industries across various sectors become increasingly competitive, businesses leverage recommendation systems to enhance user experiences, drive engagement, and boost revenue.
In the e-commerce industry, recommendation engines enable personalized product recommendations, cross-selling, and upselling. By understanding their customers’ preferences and purchase history, these systems can suggest items that align with their interests, leading to higher customer satisfaction and repeat purchases.
In the entertainment and content streaming industry, recommendation engines play a crucial role in suggesting relevant movies, TV shows, music, or articles. By analyzing a user’s behavior and preferences, platforms like Netflix, Spotify, and YouTube provide personalized recommendations that enhance users’ satisfaction and encourage them to explore more content.
Additionally, recommendation engines have become essential in improving user experiences on social media platforms, news websites, and even in the food delivery industry. These systems help users discover new and relevant information while driving user engagement and retention by presenting content or services that align with their interests.
Fortunately, implementing a recommendation engine doesn’t have to be complicated. With Redis, your company can launch a comprehensive recommendation system in no time.
Recommendation Systems Overview
Recommendation engines are statistical models that analyze user data, such as browsing history, purchase behavior, preferences, and demographics, to provide personalized recommendations. These recommendations can be in the form of product suggestions, content recommendations, or relevant services.
The significance of recommendation engines lies in their ability to cater to individual user preferences and streamline decision-making processes. By offering tailored suggestions, companies can effectively engage users, keep them on their platforms longer, and ultimately increase conversion rates and sales.
There are several types of recommendation systems commonly used in practice:
- Content-Based Filtering: This approach recommends items to users based on their preferences and characteristics. It analyzes the content and attributes of items that users have interacted with or rated positively and suggests similar items. For example, if a user enjoys action films in a movie recommendation system, the system would recommend other action movies.
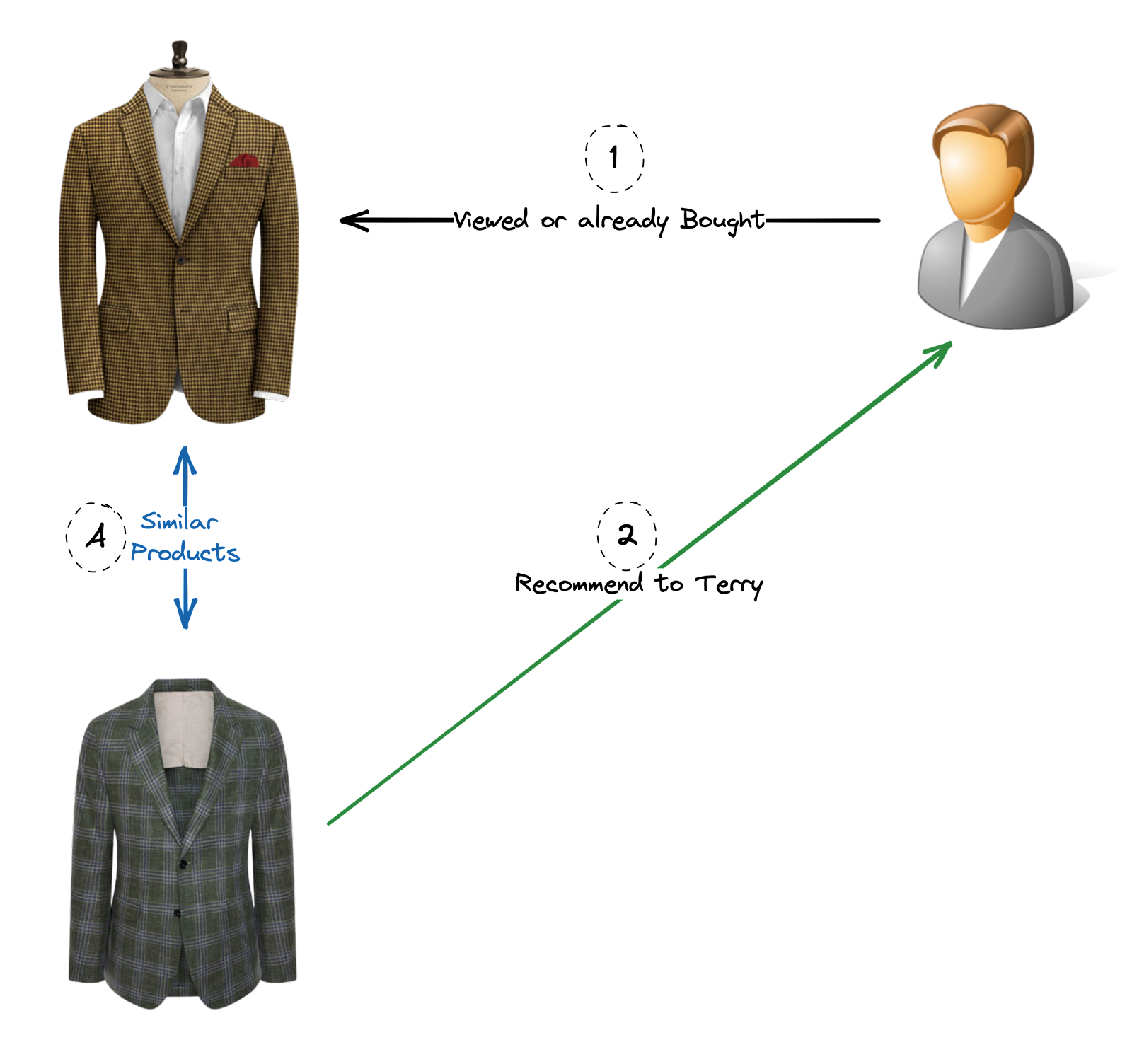
- Collaborative Filtering: This method recommends items based on the similarities and patterns found in the behavior and preferences of multiple users. It identifies users with similar tastes and recommends items that those users have liked or rated highly. Collaborative filtering can be further divided into two subtypes:
- User-Based Collaborative Filtering: It identifies users with similar preferences and recommends items that users with similar tastes have enjoyed (Scenario A & B).
- Item-Based Collaborative Filtering: It identifies items that are similar based on user behavior and recommends items that are similar to those previously interacted with by the user (Scenario C).

- Context-Aware Systems: These systems consider contextual information, such as time, location, and user context, to provide more relevant recommendations. For instance, a music streaming service might recommend energetic workout playlists in the morning and relaxing music in the evening. Likewise, an e-commerce website will suggest specific items when it’s Black Friday or Christmas, different from what it could recommend in other periods of the year.

- Hybrid Recommender Systems: These systems combine multiple recommendation techniques to provide more accurate and diverse recommendations. They leverage the strengths of different approaches, such as content-based filtering and collaborative filtering, to overcome their limitations and offer more effective suggestions.
Recommendation Engines in Redis
Unlike offline recommendation engines that generate personalized recommendations based on historical data, an ideal recommendation engine should prioritize resource efficiency, deliver high-performance real-time updates, and provide accurate and relevant choices to users. For example, it can be annoying to suggest to a customer an item it already bought only because your recommendation system wasn’t aware of the customer’s last actions.
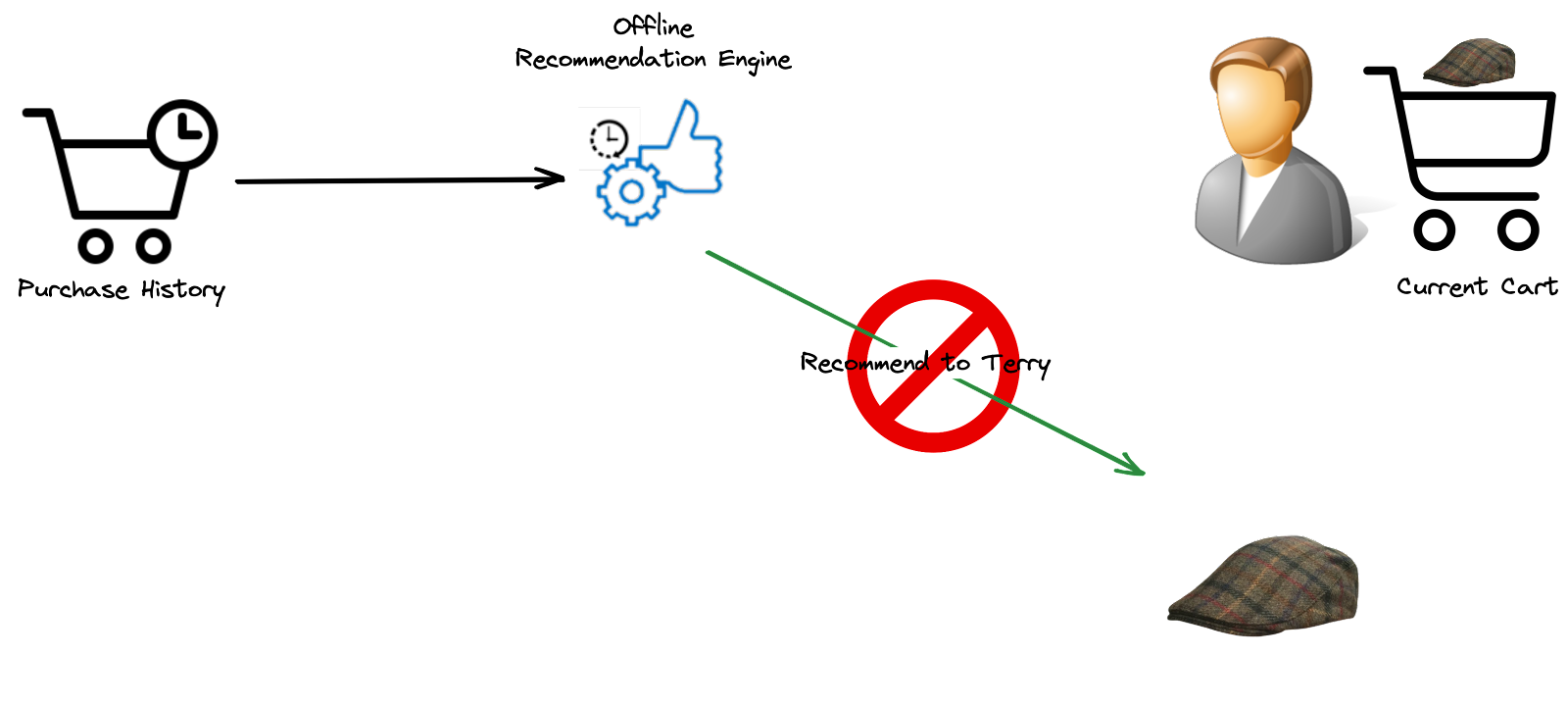
Real-time engines would react to customers’ actions while they are still browsing your site and recalculate the recommendations accordingly. This would give the customers a feeling that they have a dedicated sales assistant, making their experiences more personalized.

You clearly need a low-latency backend to implement such a real-time system. First, you need to present users’ attributes and preferences in a specific way that allows their classification into groups. Then you need a performant representation of products that provides similarity calculation and querying in very low latency.
Implementing such systems using Redis Enterprise is a straightforward task. First, you would consider user preferences, product attributes, and any other filtering parameters as vectors. Then, thanks to the similarity search feature provided by Redis, you can make distance calculations (affinity scores) between these vectors and make recommendations based on these scores.
Vectors embeddings are mathematical representations of data points where each vector dimension corresponds to a specific feature or attribute of the data. For example, a product image can be represented as a vector where each element represents the characteristic of this product (color, shape, size…). Similarly, a product description can be transformed into a vector where each element represents the frequency or presence of a specific word or term.

Vector representations of data enable machine learning algorithms to process and analyze the information efficiently. These algorithms often rely on mathematical operations performed on vectors, such as dot products, vector addition, and normalization, to compute similarities, distances, and transformations.
But most importantly, Vector representations facilitate the comparison and clustering of data points in a multi-dimensional space. Similarity measures, such as cosine similarity or Euclidean distance, can be calculated between vectors to determine the similarity or dissimilarity between data points. Thus your recommendation engine can leverage vectors to:
- cluster and classify customers according to their preferences and attributes (age, sex, job, location, income…). This can help to find similarities between customers (Collaborative Filtering)
- suggest similar products based on their images and textual descriptions (Content-Based Filtering).

1 - Creating Vector Embeddings
In order to understand how vector embeddings are created, a brief introduction to modern Deep Learning models is helpful.
It is essential to convert unstructured data into numerical representations to make data understandable for Machine Learning models. In the past, this conversion was manually performed through Feature Engineering.
Deep Learning has introduced a paradigm shift in this process. Rather than relying on manual engineering, Deep Learning models autonomously learn intricate feature interactions in complex data. As data flows through a Deep Learning model, it generates novel representations of the input data, each with varying shapes and sizes. Each layer of the model focuses on different aspects of the input. This ability of Deep Learning to automatically generate feature representations from inputs forms the foundation for creating vector embeddings.

Vector Embeddings are created through an embedding process that maps discrete or categorical data into continuous vector representations. The process of creating embeddings depends on the specific context and data type. Here are a few common techniques:
- Text Embeddings: use methods, such as Term Frequency-Inverse Document Frequency (TF-IDF), to calculate the frequency of words in a text corpus and assign weights to each word accordingly. They can use some other popular neural network-based algorithms like Word2Vec or GloVe to learn word embeddings by training neural networks on large text corpora. These algorithms capture semantic relationships between words based on their co-occurrence patterns.
- Image Embeddings: use Convolutional Neural Networks (CNN) such as VGG, ResNet, or Inception, which are commonly used for image feature extraction. The activations from intermediate layers or the output of the fully connected layers can serve as image embeddings.
- Sequential Data Embeddings: use Recurrent Neural Networks (RNN): RNNs, such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU), can learn embeddings for sequential data by capturing dependencies and temporal patterns. They can also use the Transformer model itself or its variants like BERT or GPT, which can generate contextualized embeddings for sequential data.
- User Embeddings: A user’s activity on an e-commerce marketplace is not only limited to only viewing items. Users may also perform actions such as making a search query, adding an item to their shopping cart, adding an item to their watch list, and so on. These actions provide valuable signals for the generation of personalized recommendations. You can use a Recurrent Neural Network (RNN) or Gated Recurrent Units (GRU) to encode the ordering information of historical events. For further information on model training, experiments, and deployment setup, please refer to the research paper from eBay.
These are just a few examples of how embeddings are created. Our recommendation engine uses a variant of BERT called all-mpnet-base-v2 to create sequential data embeddings for product descriptions. To generate product image embeddings, we use the Img2Vec model (an implementation of Resnet-18). Both models are hosted and runnable online, with no expertise or installation required.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
import os
import redis
# data prep
import pandas as pd
import numpy as np
# for creating image vector embeddings
import urllib.request
from PIL import Image
from img2vec_pytorch import Img2Vec
# for creating semantic (text-based) vector embeddings
from sentence_transformers import SentenceTransformer
def generate_text_vectors(products):
text_vectors = {}
# Bert variant to create text embeddings
text_model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
# generate text vector
for index, row in products.iterrows():
text_vector = text_model.encode(row["description"])
text_vectors[index] = text_vector.astype(np.float32)
return text_vectors
def generate_image_vectors(products):
img_vectors={}
images=[]
converted=[]
# Resnet-18 to create image embeddings
image_model = Img2Vec()
# generate image vector
for index, row in products.iterrows():
tmp_file = str(index) + ".jpg"
urllib.request.urlretrieve(row["image_url"], tmp_file)
img = Image.open(tmp_file).convert('RGB')
img = img.resize((224, 224))
images.append(img)
converted.append(index)
vec_list = image_model.get_vec(images)
img_vectors = dict(zip(converted, vec_list))
return img_vectors
def create_product_catalog():
# initialize product
dataset = {
'id': [1253, 9976, 3626, 2746],
'description': ['Herringbone Brown Classic', 'Herringbone Wool Suit Navy Blue', 'Peaky Blinders Tweed Outfit', 'Cable Knitted Scarf and Bobble Hat'],
'image_url': [
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/donegal-herringbone-tweed-men_s-jacket.jpeg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Mens-Herringbone-Tweed-Check-3-Piece-Wool-Suit-Navy-Blue.webp',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Marc-Darcy-Enzo-Mens-Herringbone-Tweed-Check-3-Piece-Suit.jpeg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Mocara_MaxwellFlat_900x.jpg'
]
}
# Create DataFrame
products = pd.DataFrame(dataset).set_index('id')
return products
def create_product_vectors(products):
product_vectors = []
img_vectors = generate_image_vectors(products)
text_vectors = generate_text_vectors(products)
for index, row in products.iterrows():
_id = index
text_vector = text_vectors[_id].tolist()
img_vector = img_vectors[_id].tolist()
vector_dict = {
"text_vector": text_vector,
"img_vector": img_vector,
"product_id": _id
}
product_vectors.append(vector_dict)
return product_vectors
def store_product_vectors(redis_conn, product_vectors):
for product in product_vectors:
product_id = product["product_id"]
key = "product_vector:" + str(product_id)
redis_conn.hset(
key,
mapping={
"product_id": product_id,
# add image and text vectors as blobs
"img_vector": np.array(product["img_vector"], dtype=np.float32).tobytes(),
"text_vector": np.array(product["text_vector"], dtype=np.float32).tobytes()
})
def create_redis_conn():
host = os.environ.get("REDIS_HOST", "localhost")
port = os.environ.get("REDIS_PORT", 6379)
db = os.environ.get("REDIS_DB", 0)
password = os.environ.get("REDIS_PASSWORD", "vss-password")
url =f"redis://:{password}@{host}:{port}/{db}"
redis_conn = redis.from_url(url)
return redis_conn
# Create a Redis connection
redis_conn = create_redis_conn()
# Create a few products
products = create_product_catalog()
# Create vector embeddings for products
product_vectors = create_product_vectors(products)
# Store vectors in Redis
store_product_vectors(redis_conn, product_vectors)
To create User embeddings, you can leverage the Two-Tower Neural Networks approach. It consists of two separate neural network models, often called “towers,” that process different types of input data in parallel.
The two towers in the network typically receive different types of information related to user-item interactions. For example, one tower might process user-specific data, such as demographic information or past preferences, while the other tower processes item-specific data, such as product descriptions or attributes. Each tower independently learns representations or features from its respective input data using multiple layers of interconnected artificial neurons. The output of each tower’s final layer is then combined or fused to generate a joint representation that captures the relationship between users and items. In the rest of this article, I will omit this part.

The choice of embedding technique depends on the specific data type, task, and available resources. The Huggingface Model Hub contains many models that can create embeddings for different kinds of data.
2 - Vector Embeddings Indexing
Once you have created your embeddings, you need to store them in a Vector database. Various technologies support the storage of vector embeddings, including Pinecone, Milvus, Weaviate, Vespa, Chroma, Vald, Quadrant, etc. Redis can also serve as a vector database. It manages vectors in an index data structure to enable intelligent similarity search that balances search speed and search quality. Redis supports two types of vector indexing:
- FLAT: A brute force approach that searches through all possible vectors. This indexing is simple and effective for small datasets or cases where interpretability is important;
- Hierarchical Navigable Small Worlds (HNSW): An approximate search that yields faster results with lower accuracy. This is more suitable for complex tasks that require capturing intricate patterns and relationships, especially with large datasets.
The choice between Flat and HNSW depends only on your usage, data characteristics, and requirements.
Indexes only need to be created once and will automatically re-index as new hashes are stored in Redis. Both indexing methods have the same mandatory parameters: Type, Dimension, and Distance Metric.
Redis Enterprise uses a distance metric to measure the similarity between two vectors. Choose from three popular metrics – Euclidean (L2), Inner Product (IP), and Cosine Similarity – used to calculate how “close” or “far apart” two vectors are.

Below is an example of creating image and text indexes in Redis based on the vectors created earlier.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
from redis import redis
from redis.commands.search.field import VectorField
from redis.commands.search.indexDefinition import (
IndexDefinition,
IndexType
)
# Function to create a HNSW search index with Redis/RediSearch
def create_hnsw_index(
redis_conn,
number_of_vectors: int,
prefix: str,
distance_metric: str='COSINE'
):
image_field = VectorField("img_vector",
"HNSW", {
"TYPE": "FLOAT32",
"DIM": 512,
"DISTANCE_METRIC": distance_metric,
"INITIAL_CAP": number_of_vectors
})
text_field = VectorField("text_vector",
"HNSW", {
"TYPE": "FLOAT32",
"DIM": 768,
"DISTANCE_METRIC": distance_metric,
"INITIAL_CAP": number_of_vectors
})
redis_conn.ft('idx').create_index(
fields = [image_field, text_field],
definition = IndexDefinition(prefix=[prefix], index_type=IndexType.HASH)
)
# Create an HNSW search index for the products created earlier.
create_hnsw_index(redis_conn, 4, 'product_vector:')
After vectors are loaded into Redis and indexes have been created, queries can be formed and executed for all kinds of similarity-based search tasks.
3 - Vector Similarity Search
Redis Vector Similarity Search (VSS) is a new feature built on top of the RediSearch Module. It allows developers to store and index vectors and make queries on them just as easily as any other field in a Redis hash or JSON.
Consequently, Redis exposes the usual search functionality, combining full text, tag, and numeric pre-filters with K Nearest Neighbors (KNN) vector search: With Redis VSS, you can query vector data stored as BLOBs in Redis hashes and choose the relevant vector distance metrics to calculate how “close” or “far apart” two vectors are.

In addition, it provides advanced search capabilities like finding the “top K” most similar vectors performing low-latency searches in large vector spaces by ranging from tens of thousands to hundreds of millions of vectors distributed across several machines.
You can use vector similarity queries in the FT.SEARCH query command. You must specify the option DIALECT 2 or greater to use a vector similarity query. There are two types of vector queries: KNN and range:
- KNN search: This is useful to find the K-Nearest Neighbors of a specific vector. The syntax for vector similarity KNN queries is
*=>[<vector_similarity_query>]for running the query on an entire vector field, or<primary_filter_query>=>[<vector_similarity_query>]for running the similarity query on the result of the primary filter query. For example, the following query returns the 10 closest images for which the vector stored under its img_vec field is the most relative to the vector represented by the following 4-byte blob.
FT.SEARCH idx "*=>[KNN 10 @img_vec $BLOB]" PARAMS 2 BLOB "\x12\xa9\xf5\x6c" DIALECT 2
- Range queries: filter query results by the distance between a vector field value and a query vector in terms of the relevant vector field distance metric. The syntax for range query is
@<vector_field>: [VECTOR_RANGE (<radius> | $<radius_attribute>) $<blob_attribute>]. Range queries can appear multiple times in a query, similar toNUMERICandGEOclauses, and in particular, they can be a part of the<primary_filter_query>in KNN Hybrid search. For example, you can make a query that returns similar products of a given item available in stores around your home!
In the example below, we return the same result as the previous query, but we specify the distance between the image vector stored under the img_vec field and the specified query vector blob no more than 0.2 (aka. 80% of similarity score in terms of img_vec field DISTANCE_METRIC).
FT.SEARCH idx "@img_vec:[VECTOR_RANGE 0.2 $BLOB]" PARAMS 3 BLOB "\x12\xa9\xf5\x6c" LIMIT 0 10 DIALECT 2
Below is an example of creating a query with redis_py that returns the 3 most similar products (by image) to this one, sorted by relevance score (cosine similarity set in the indexes created earlier).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import numpy as np
from redis.commands.search.query import Query
# for creating query vector embeddings
import urllib.request
from PIL import Image
from img2vec_pytorch import Img2Vec
# Function to create the query parameter (query_vector)
def create_query_vector():
query_image_url = "https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/test_image.jpg"
# Resnet-18 to create image embeddings
image_model = Img2Vec()
# generate image vector
tmp_file = "query_image.jpg"
urllib.request.urlretrieve(query_image_url, tmp_file)
img = Image.open(tmp_file).convert('RGB')
img = img.resize((224, 224))
vector = image_model.get_vec(img)
query_vector = np.array(vector, dtype=np.float32).tobytes()
return query_vector
# Function to create the search query
def create_query(
return_fields: list,
search_type: str="KNN",
number_of_results: int=3,
vector_field_name: str="img_vector"
):
query_str = f'*=>[{search_type} {number_of_results} @{vector_field_name} $query_vector]'
return Query(query_str)\
.sort_by('__img_vector_score')\
.paging(0, number_of_results)\
.return_fields(*return_fields)\
.dialect(2)
params_dict = {"query_vector" : create_query_vector()}
results = redis_conn.ft('idx').search(create_query(['product_id', '__img_vector_score']), query_params=params_dict)
print(results)
You can try this out! The instructions above are a brief overview to demonstrate the building blocks for a real-time recommendation engine using Redis. I recommend two projects that leverage the VSS capability in Redis. The first one is the Fashion Product Finder implemented using redis-om-python.

{kind=link}
The second one is a project that uses Redis Vector Similarity Search to return similarities on an Amazon real dataset and provides:
- Semantic Search: Given a sentence, check products with semantically similar text in the product keywords;
- Visual Search: Given a query image, find the Top K most “visually” similar in the catalog.
Summary
Redis supports diverse capabilities that can significantly reduce application complexity while delivering consistently high performance, even on a large scale. Because it is an in-memory database, Redis delivers very high throughput with sub-millisecond latency, using the lowest possible computational resources.
With the Vector Similarity Search feature, Redis unlock several business-revolutionizing applications based on similarity and distance calculation in real time. Recommendation engines are simple examples of such applications.
If you want to provide interactive, content-based recommendations, you might want to take advantage of Redis as a vector database and a similarity search engine. Regardless of how complex you want your recommendation engine to be: collaborative, content-based, contextual, or even hybrid - Redis can perform all the computations required and helps you determine how best to deliver recommendations.
References
- Vector-Similarity-Search from Basics to Production, Sam Partee.
- VSS documentation, redis.io
- Personalized Embedding-based e-Commerce Recommendations at eBay, eBay (arxiv.org).
- Announcing ScaNN: Efficient Vector Similarity Search, Google Search.