In the previous post, we ventured into the captivating worlds of vector databases and vector similarity search. You witnessed the transformative potential they offer in storing and retrieving unstructured data, unlocking new dimensions of understanding in various domains.
Today, we embark on a new expedition—one that takes you beyond the boundaries of singular search methods. We delve into the realm of “Hybrid Search,” a multifaceted approach that synergizes the strengths of vector similarity search with a rich tapestry of other search paradigms. In this article, we will explore how hybrid search harnesses the power of diverse search techniques, such as textual, numerical, conditional, geographical, and more, to provide holistic solutions for information retrieval.
RediSearch: a versatile search engine
RediSearch is a Redis module that provides querying, secondary indexing, and full-text search for Redis. Written in C, Redis Search is extremely fast compared to other open-source search engines. It implements multiple data types and commands that fundamentally change what you can do with Redis. RediSearch supports capabilities for search and filtering, such as geospatial queries, filtering by numeric ranges, retrieving documents by specific fields, and custom document scoring. Aggregations can combine map, filter, and reduce/group-by operations in custom pipelines that instantly run across millions of elements.
RediSearch also supports auto-completion with fuzzy prefix matching and atomic real-time insertion of new documents to a search index. With the latest RediSearch release, creating a secondary index on top of your existing data is easier than ever. You can just add Search and Query capabilities to your existing Redis database, create an index, and start querying it without migrating your data or using new commands for adding data to the index. This drastically lowers the learning curve for new users and lets you create indexes on your existing Redis databases—without even restarting them.
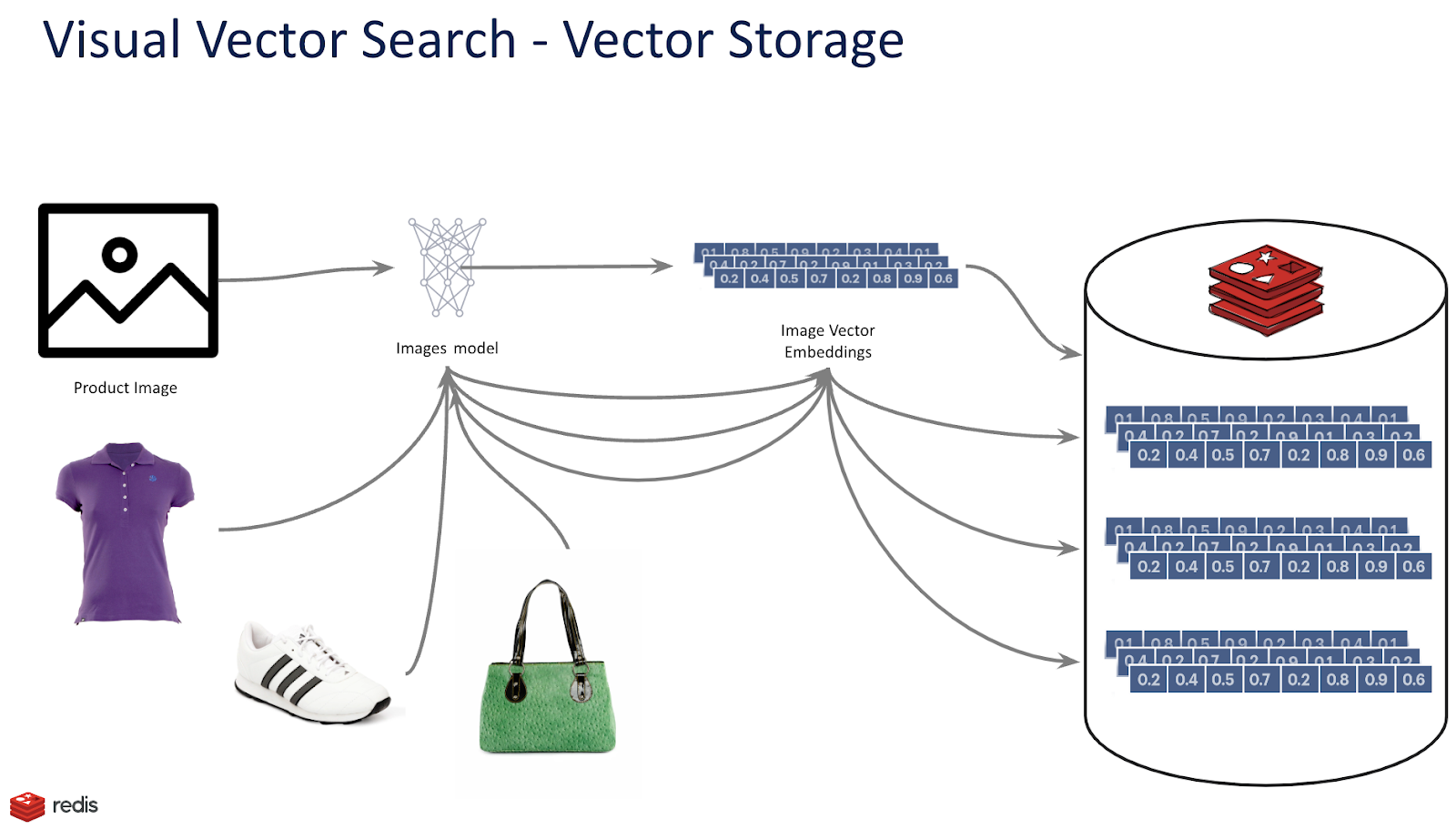
In addition, as a versatile search engine, RediSearch offers the technical foundations to store, index, and query vector embeddings. It provides advanced indexing and search capabilities required to perform low-latency searches in large vector spaces, typically ranging from tens of thousands to hundreds of millions of vectors distributed across a number of machines.

Vector Similarity Search focuses on finding out how alike or different two vectors are. Once you have created your embeddings and stored them in Redis, you must create an index data structure to enable intelligent similarity search that balances search speed and search quality. Redis supports two types of vector indexing:
- FLAT: A brute force approach using the K-Nearest Neighbor (KNN) search through all possible vectors. This indexing is simple and effective for small datasets or cases where interpretability is important;
- Hierarchical Navigable Small Worlds (HNSW): An approximate search (ANN) that yields faster results with lower accuracy. This is more suitable for complex tasks that require capturing intricate patterns and relationships, especially with large datasets.
The choice between Flat and HNSW depends only on your usage, data characteristics, and requirements. Indexes only need to be created once and will automatically re-index as new hashes are stored in Redis. Both indexing methods have the same mandatory parameters: Type, Dimension, and Distance Metric.
Distance metrics provide a reliable and measurable way to calculate the similarity or dissimilarity of two vectors. You can use many Distance metrics for similarity score calculation, but currently, only the Euclidean (L2), Inner Product (IP), and Cosine Similarity metrics are available in Redis.
Hybrid Search
RediSearch exposes the usual search capabilities, combining full text, geographical, and numeric pre-filters along with the K Nearest Neighbors (KNN) vector search. For this, you can use vector similarity queries in the FT.SEARCH query command and you must specify the option DIALECT 2 or greater to use a vector similarity query. For example, you can make a query that returns similar products of a given item by its image available in stores around your home!
Let’s consider the following product object. It consists of the product image, name, vector embedding of the product image, gender, and the store location in which you can find this product:
1
2
3
4
5
6
7
8
9
{
"product_id": "8cf52572340c3592e5f0ede116a0206f",
"product_embedding": [3.0499367713928223,0.6722652912139893,1.209347128868103,0.4089492857456207,0.00762720312923193,0.16665008664131165,0.23197419941425323,0.7637760639190674,...],
"product_name": "Numero Uno Men White Casual Shoes",
"product_image": "drive/MyDrive/ColabDrive/products/men/8cf52572340c3592e5f0ede116a0206f.jpg",
"gender": "men",
"price": 18.99,
"location": "50.69098, 3.17655"
}
For each store, multiple documents exist following the structure above and representing each product available in the store. Now, let’s create a search index to query the different attributes of the product:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
from redis.commands.search.field import (
TagField,
VectorField,
TextField,
NumericField,
GeoField
)
from redis.commands.search.indexDefinition import (
IndexDefinition,
IndexType
)
# Function to create a hybrid search index with Image Vector Search + Tag Filtering
def create_hybrid_index(
redis_conn,
vector_field_name: str,
number_of_vectors: int,
index_name:str,
prefix: str,
distance_metric: str='COSINE'
):
# Construct index
try:
redis_client.ft(index_name).info()
print("Existing index found. Dropping and recreating the index", flush=True)
redis_client.ft(index_name).dropindex(delete_documents=False)
except:
print("Creating new index", flush=True)
gender_field = TagField('$.gender', as_name='gender')
name_field = TextField('$.product_name', no_stem=True, as_name='name')
url_field = TextField('$.product_image', no_stem=True, as_name='image')
price_field = NumericField('$.price', as_name='price')
location_field = GeoField('$.location', as_name='location')
image_field = VectorField(f"{vector_field_name}", "FLAT",
{
"TYPE": "FLOAT32",
"DIM": 512,
"DISTANCE_METRIC": distance_metric,
"INITIAL_CAP": number_of_vectors
}, as_name='vector')
redis_conn.ft(index_name).create_index(
fields = [gender_field, name_field, url_field, price_field, location_field, image_field],
definition = IndexDefinition(prefix=[prefix], index_type=IndexType.JSON)
)
You can start testing this index by performing some basic full-text searches. First, find all products with the keyword Addidas. Note we voluntarily make a typo in the brand name Adidas to test the fuzzy search. The executed search query is:
1
2
3
4
5
query = (
Query('@name:%addidas%').return_fields('id', 'name', 'image', 'price')
)
results = redis_client.ft("product_index").search(query)
Now, we will look for the same products with a filter on price: Only product that costs less or equal to 50 euros. The executed search query is:
1
2
3
4
5
query = (
Query('@name:%Adidas% @price:[0 50]').return_fields('id', 'name', 'image', 'price')
)
results = redis_client.ft("product_index").search(query)
Now, we can make hybrid searches using vector similarity search and standard search. For this, we will start by looking for all products that are similar to a given image (a product image), and we will specify a pre-filtering condition to limit the search to a certain category of products (e.g., gender, footwear…). For this, we create a helper function called hybrid_similarity_search to create an embedding from the query image and compare it to other vectors having the same prefix according to the index created previously, in addition to filtering by the gender tag.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def hybrid_similarity_search(query_image: str, query_tag: str, k: int, return_fields: tuple, index_name: str = "product_index") -> list:
# create a redis query object
redis_query = (
Query(f"(@gender:{query_tag})=>[KNN {k} @vector $query_vector AS distance]")
.sort_by("distance")
.return_fields(*return_fields)
.paging(0, k)
.dialect(2)
)
# create embedding from query text
query_vector = np.array(generate_image_vector(query_image), dtype=np.float32).tobytes()
# execute the search
results = redis_client.ft(index_name).search(
redis_query, query_params={"query_vector": query_vector}
)
1
2
3
4
5
6
# 2. Create query arguments
query_image = "drive/MyDrive/ColabDrive/products/input/2eca615a43d0098f4bb5fc90004c3678.jpg"
query_tag = "women"
# 3. Perform the hybrid vector similarity search with the given parameters
results = hybrid_similarity_search(query_image, query_tag, k=3, return_fields=('distance', '$.product_id', '$.product_image', '$.gender'))
The expected result is a dataframe containing only women items similar to the given input image.

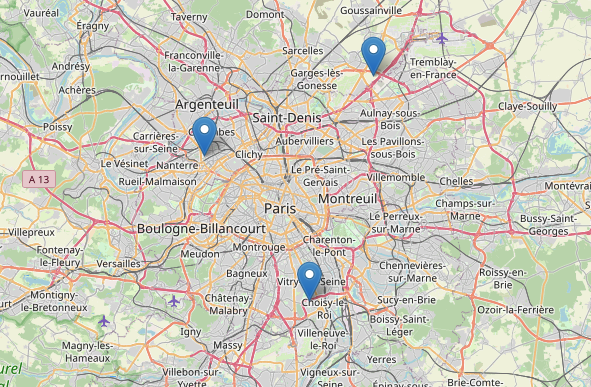
Similarly, looking for products that are similar to a given one and available in stores near a given location is a simple query. For this, let’s update the previous helper function to make pre-filtering by locations around Paris with a radius of 30 km.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def hybrid_similarity_search(query_image: str, location: str, radius: str, k: int, return_fields: tuple, index_name: str = "product_index") -> list:
# create a redis query object
redis_query = (
Query(f"(@location:[{location} {radius}])=>[KNN {k} @vector $query_vector AS distance]")
.sort_by("distance")
.return_fields(*return_fields)
.paging(0, k)
.dialect(2)
)
# create embedding from query text
query_vector = np.array(generate_image_vector(query_image), dtype=np.float32).tobytes()
# execute the search
results = redis_client.ft(index_name).search(
redis_query, query_params={"query_vector": query_vector}
)
1
2
3
4
5
6
7
# 2. Create query arguments
query_image = "drive/MyDrive/ColabDrive/products/input/2eca615a43d0098f4bb5fc90004c3678.jpg"
paris_coordinates = "48.866667 2.333333"
radius = "30 km"
# 3. Perform the hybrid vector similarity search with the given parameters
results = hybrid_similarity_search(query_image, paris_coordinates, radius, k=3, return_fields=('distance', '$.product_id', '$.product_image', '$.product_name', '$.location'))
The example above returns the same result as the previous query. Still, we specify the coordinates of Paris and the radius in which we want to perform the search between the given image vector and all the products’ vectors already stored in Redis. The result can be displayed on a map for a more user-friendly interface.
You can imagine the multiple usages you can unlock with a hybrid search. For example, You can use it In the e-commerce industry, with recommendation engines to enable personalized product recommendations, cross-selling, and upselling. These systems help users discover new and relevant information while driving user engagement and retention by presenting content or services that align with their interests, thus improving overall user experiences.
Redis combines the power of searching structured, semi-structured, and unstructured data within a single performant search engine. This is translated to flat learning curves and a more consolidated technological stack within your organization, in addition to the well-known Redis sub-millisecond performance.

The instructions above are a brief overview to demonstrate the building blocks for Vector Similarity Search using Redis. You can try this out with the notebook referenced here: ![]()
Summary
In this exploration of hybrid search, we’ve delved into the captivating world of Redis and RediSearch, discovering how they empower us to master the search multiverse. We began by revisiting vector similarity search, a powerful technique for finding similarities between vectors, and saw how Redis, through the RediSearch module, can be used to implement it efficiently.
We then ventured into the realm of hybrid search, where the fusion of vector similarity search with other search paradigms opens up a wealth of possibilities. Whether combining full-text, geographical, and numeric pre-filters with vector search or creating dynamic queries to find similar products based on images, Redis and RediSearch provide the tools to navigate this multifaceted landscape.
As we conclude this journey, we find ourselves at the intersection of innovation and efficiency. Redis and RediSearch offer a versatile solution that consolidates your technology stack, simplifies the learning curve, and delivers sub-millisecond performance. Whether you’re in the realm of e-commerce, healthcare, finance, or any domain where data exploration is paramount, mastering the hybrid search with Redis is your key to unlocking deeper insights and creating exceptional user experiences.
References
- Searching document data with Redis, JSON, and vector-similarity, Brian Sam-Bodden.
- VSS documentation, redis.io