Data Processing involves transforming raw data into useful insights through analysis techniques like machine learning algorithms or statistical models depending on what type of problem needs solving within an organization’s context.
Data processing is the core of any data architecture. The aim here is not only accuracy but also efficiency since this stage requires significant computing power, which could become costly over time without proper optimization strategies.
In this stage, raw data, already extracted from data sources, are prepared and transformed into the specific format required by the downstream systems. We will see that while data is going further in this stage, it gains in value and can offer better insights for decision-making.
In this post, we will cover data processing using the Redis toolset. Redis is an open-source, in-memory datastore used as a database, cache, streaming engine, and message broker. It supports various data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. In addition, Redis provides a sub-millisecond latency with very high throughput: up to 200M Ops/sec at a sub-millisecond scale, which makes it the obvious choice for real-time use cases.
Pre-requisites
1 - Create a Redis Database
You need to install and set up a few things for this article. First, you need to prepare a Redis Enterprise Cluster as storage support. This storage support will be the target infrastructure for the data transformed in this stage. You can use this project to create a Redis Enterprise cluster in the cloud provider of your choice.
Once you have created a Redis Enterprise cluster, you must create a target database that holds the transformed data. Redis Enterprise Software lets you create and distribute databases across a cluster of nodes. To create a new database, follow the instructions here. We assume that for this blog post, you will use a database with the endpoint: redis-12000.cluster.redis-process.demo.redislabs.com:12000
2 - Install RedisGears
Now, let’s install RedisGears on the cluster. In case it’s missing, follow this guide to install it.
1
2
3
4
mkdir ~/tmp
curl -s https://redismodules.s3.amazonaws.com/redisgears/redisgears.Linux-ubuntu18.04-x86_64.1.2.5.zip -o ~/tmp/redis-gears.zip
cd ~/tmp
curl -v -k -s -u "<REDIS_CLUSTER_USER>:<REDIS_CLUSTER_PASSWORD>" -F "module=@./redis-gears.zip" https://<REDIS_CLUSTER_HOST>:9443/v2/modules
Data processing using RedisGears
1 - RedisGears: Introduction
RedisGears is a data processing engine in Redis. It supports transaction, batch, and event-driven processing. RedisGears runs as a module inside a Redis server and is operated via a set of Redis commands. So to run it, you’ll need a Redis server (v6 or greater) and the module’s shared library, then you write functions that describe how your data should be processed. You then submit this code to your Redis deployment for remote execution.
When the Redis Gears module is loaded onto the Redis engines, the Redis engine command set is extended with new commands to register, distribute, manage, and run so-called Gear Functions, written in Python, across the shards of the Redis database.
Client applications can define and submit such Python Gear Functions, either to run immediately as batch jobs or to be registered to be triggered on events, such as Redis keyspace changes, stream writes, or external triggers. The Redis Gears module handles all the complexities of distribution, coordination, scheduling, execution, and result collection and aggregation of the Gear Functions.
The engine can execute functions in an ad-hoc batch-like fashion or triggered by different events for event-driven processing. In addition, the data stored in the database can be read and written by functions, and a built-in coordinator facilitates the processing of distributed data in a cluster.
The first step/operation of any Gear Function is always one of six available “Readers” that operate on different types of input data:
- KeysReader: Redis keys and values.
- KeysOnlyReader: Redis keys.
- StreamReader: Redis Stream messages.
- PythonReader: Arbitrary Python generator.
- ShardsIDReader: Shard ID.
- CommandReader: Command arguments from the application client.
Readers can be parameterized to narrow down the subset of data it should operate on, for example, by specifying a pattern for the keys or streams it should read.
Depending on the reader type, Gear Functions can either be run immediately, on demand, as batch jobs, or in an event-driven manner by registering it to trigger automatically on various types of events.
Gear Functions are composed of a sequence of steps or operations, such as Map, Filter, Aggregate, GroupBy, and more. These operations are parameterized with Python functions that you define according to your needs.
An operation is the building block of Gears functions. Different operation types can be used to achieve a variety of results to meet various data processing needs. Operations can have zero or more arguments that control their operation. Depending on the operation’s type, arguments may be language-native data types and function callbacks.
The steps/operations are “piped” together by the Redis Gears runtime such that the output of one step/operation becomes the input to the subsequent step/operation, and so on.
An action is a special type of operation that is always the function’s final step. There are two types of actions:
- Run: runs the function immediately in batch
- Register: registers the function’s execution to be triggered by an event
Each shard of the Redis Cluster executes its own ‘instance’ of the Gear Function in parallel on the relevant local shard data unless explicitly collected or until it is implicitly reduced to its final global result at the end of the function.

2 - RedisGears: first steps
The simplest way to write and execute a Gears Function can be done using the Redis client interface (redis-cli).
Once at the redis-cli prompt, type in the following and then hit the <ENTER> to execute it:
1
2
3
4
5
$ redis-cli -h cluster.redis-process.demo.redislabs.com -p 12000
cluster.redis-process.demo.redislabs.com:12000> RG.PYEXECUTE "GearsBuilder().run()"
1) (empty array)
2) (empty array)
The RedisGears function you’ve just executed had replied with an empty results array because it had no input to process (the database is empty). The initial input to any RedisGears function can be zero, one or more records that are generated by a reader.
A Record is the basic RedisGears abstraction representing data in the function’s flow. Input data records are passed from one step to the next and are finally returned as a result.
A Reader is the mandatory first step of any function, and every function has exactly one reader. First, a reader reads data and generates input records from it. Then, the input records are consumed by the function.
There are several reader types that the engine offers. A function’s reader type is always declared during the initialization of its GearsBuilder() context. Unless explicitly declared, a function’s reader defaults to the KeysReader, meaning the following lines are interchangeable:
1
2
3
4
GearsBuilder() # The context builder's default is
GearsBuilder('KeysReader') # the same as using the string 'KeysReader'
GearsBuilder(reader='KeysReader') # and as providing the 'reader' argument
GB() # GB() is an alias for GearsBuilder()
Let’s add a pair of Hashes representing fictitious personas and a hash that represents a country. Execute these Redis commands :
1
2
3
HSET person:1 name "Rick Sanchez" age 70
HSET person:2 name "Morty Smith" age 14
HSET country:FR name "France" continent "Europe"
Now that the database has three keys, the function returns three result records, one for each.
1
2
3
4
5
6
cluster.redis-process.demo.redislabs.com:12000> RG.PYEXECUTE "GearsBuilder().run()"
1) 1) "{'event': None, 'key': 'person:1', 'type': 'hash', 'value': {'age': '70', 'name': 'Rick Sanchez'}}"
2) "{'event': None, 'key': 'person:2', 'type': 'hash', 'value': {'age': '14', 'name': 'Morty Smith'}}"
3) "{'event': None, 'key': 'country:FR', 'type': 'hash', 'value': {'continent': 'Europe', 'name': 'France'}}"
2) (empty array)
By default, the KeysReader reads all keys in the database. This behavior can be controlled by providing the reader with a glob-like pattern that, upon the function’s execution, is matched against every key name. The reader generates input records only for the keys with names that successfully match the pattern.
The reader’s key names’ pattern is set to “*” by default, so any key name matches it. One way to override the default pattern is from the context’s run() method. To have input records consisting only of persons, we can use the pattern person:* to discard keys that don’t match it by providing it like so:
1
2
3
4
5
cluster.redis-process.demo.redislabs.com:12000> RG.PYEXECUTE "GearsBuilder().run('person:*')"
1) 1) "{'event': None, 'key': 'person:1', 'type': 'hash', 'value': {'age': '70', 'name': 'Rick Sanchez'}}"
2) "{'event': None, 'key': 'person:2', 'type': 'hash', 'value': {'age': '14', 'name': 'Morty Smith'}}"
2) (empty array)
The reader can generate any number of input records as its output. These records are used as input for the next step in the flow, in which the records can be operated upon in some manner and then output. Multiple steps can be added to the flow, meaningfully transforming its input records to one or more output records.
To see how this works in practice, we’ll refactor our function to use a filter() operation as a step instead of the reader’s keys pattern:
1
2
3
4
5
cluster.redis-process.demo.redislabs.com:12000> RG.PYEXECUTE "GearsBuilder().filter(lambda x: x['key'].startswith('person:')).run()"
1) 1) "{'event': None, 'key': 'person:1', 'type': 'hash', 'value': {'age': '70', 'name': 'Rick Sanchez'}}"
2) "{'event': None, 'key': 'person:2', 'type': 'hash', 'value': {'age': '14', 'name': 'Morty Smith'}}"
2) (empty array)
The filter() operation invokes the filtering function once for every input record it gets. The input record denoted as x in the examples, is a dictionary in our case and the function checks whether the value of its key key conforms to the requested pattern.
The main difference between the function that uses the reader’s key pattern and the one using the step is when the filtering act happens. In the key pattern’s case, filtering is done by the reader itself - after it obtains the keys’ names but before reading their values. Conversely, with the filter() operation in the flow, the reader reads all keys (and their values) that are only then turned into records and filtered by the step.
Functions can be as complex as needed and can consist of any number of steps that are executed sequentially. Furthermore, RedisGears Python API allows the use of all of the language’s features, including importing and using external packages. This brings us to the second way to write and execute a Gears Function.
Typing it into the prompt (redis-cli) is already becoming tiresome. You can imagine when you have complex data processing logic to implement. For this reason, instead of using the interactive mode, you can store your functions’ code in a regular text file and have the redis-cli send its contents for execution.
cat myFunction.py | redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -x RG.PYEXECUTE
3 - RedisGears: Batch processing
Once the data is collected in Redis, it might then enter the data preparation stage. Data preparation, often referred to as “pre-processing”, is the stage at which raw data is cleaned up and organized for the following stages of data processing. For this, RedisGears allows a few operations to help filter errors and invalid values, then prepare data for the next steps. This step aims to eliminate bad data (redundant, incomplete, or incorrect data) and create high-quality data for the best data-driven decision-making.
Remember this CSV file that we ingested in Redis (see Data & Redis part 1)
| AirportID | Name | City | Country | IATA | ICAO | Latitude | Longitude | Altitude | Timezone | DST | Tz | Type | Source |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Goroka Airport | Goroka | Papua New Guinea | GKA | AYGA | -6.081689834590001 | 145.391998291 | 5282 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 2 | Madang Airport | Madang | Papua New Guinea | MAG | AYMD | -5.20707988739 | 145.789001465 | 20 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 3 | Mount Hagen Kagamuga Airport | Mount Hagen | Papua New Guinea | HGU | AYMH | -5.826789855957031 | 144.29600524902344 | 5388 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 4 | Nadzab Airport | Nadzab | Papua New Guinea | LAE | AYNZ | -6.569803 | 146.725977 | 239 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 5 | Port Moresby Jacksons International Airport | Port Moresby | Papua New Guinea | POM | AYPY | -9.443380355834961 | 147.22000122070312 | 146 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 6 | Wewak International Airport | Wewak | Papua New Guinea | WWK | AYWK | -3.58383011818 | 143.669006348 | 19 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
We used RIOT-File to batch-ingest that CSV file into Redis as JSON objects. The objects were prefixed by the airport, and AirportID was the primary key.
Let’s imagine that only airports in a Radius of 2,000 Km from Paris are relevant to keep in the dataset. RedisGears can process the raw dataset as a batch chunk airport:* and creates a Redis geo set with the create_geo_set function. This data structure is useful for finding nearby points within a given radius or bounding box. We use it to filter the airports and keep only ones in a radius of 2,000 km from the coordinates of Paris (Longitude: 2.3488, Latitude: 48.85341) as detailed in the paris_nearest_airports function. Finally, RedisGears drops all airports not in this specific radius and returns the count of the removed airports from the dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import json
def create_geo_set(key):
airport = json.loads(execute("JSON.GET", key))
execute("GEOADD", "geoAirport", airport["Longitude"], airport["Latitude"], key)
return key
def paris_nearest_airports(dist):
paris_long = 2.3488
paris_lat = 48.85341
return execute("GEORADIUS", "geoAirport", paris_long, paris_lat, dist, "km")
GearsBuilder()\
.map(lambda x: x['key'])\
.map(lambda y: create_geo_set(y))\
.filter(lambda z: (z not in paris_nearest_airports(2000)))\
.map(lambda e: execute('JSON.DEL', e))\
.count()\
.run("airport:*")
## Expected result: [289]
Additionally, you can use RedisGears to eliminate inaccurate information and fill in any gaps. This includes eliminating unnecessary details, removing duplicates and corrupted/incorrectly formatted data, correcting outliers, filling empty fields with appropriate values, and masking confidential entries.
Let’s create the hashes that represent a few personas:
1
2
3
4
5
HSET person:1 name "Rick Sanchez" age 70
HSET person:2 name "Morty Smith" age 14
HSET person:3 name "Summer Smith" age 17
HSET person:4 name "Beth Smith" age 35
HSET person:5 name "Shrimply Pibbles" age 87
You can use the following RedisGears function to format the dataset and get the first and last names split into different fields.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def split_name(key):
person_name = execute("HGET", key, "name")
first_name = person_name.split(' ')[0]
last_name = person_name.split(' ')[1]
execute("HMSET", key, "fname", first_name, "lname", last_name)
execute("HDEL", key, "name")
return execute("HGETALL", key)
GearsBuilder()\
.map(lambda x: x['key'])\
.map(split_name)\
.collect()\
.run("person:*")
## Expected result:
# 1) "['age', '35', 'fname', 'Beth', 'lname', 'Smith']"
# 2) "['age', '70', 'fname', 'Rick', 'lname', 'Sanchez']"
# 3) "['age', '87', 'fname', 'Shrimply', 'lname', 'Pibbles']"
# 4) "['age', '14', 'fname', 'Morty', 'lname', 'Smith']"
# 5) "['age', '17', 'fname', 'Summer', 'lname', 'Smith']"
The time it takes to execute a function depends on its input and complexity. Therefore, RedisGears performs batch functions asynchronously in a thread running in the background, thus allowing the main Redis process to continue serving requests while the engine is processing.
The default behavior for RG.PYEXECUTE is to block the client that had called. A blocked client waits for the server’s reply before continuing, and in the case of a RedisGears function, that means until processing is complete. Then, any generated results are returned to the client and unblocked.
Blocking greatly simplifies the client’s logic, but for long-running tasks, it is sometimes desired to have the client continue its work while the function is executed. RedisGears batch functions can be executed in this non-client-blocking mode by adding the UNBLOCKING argument to the RG.PYEXECUTE command. For example, we can run the first version of our simple function in a nonblocking fashion like so:
1
2
$ cat myFunction.py | redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -x RG.PYEXECUTE UNBLOCKING
"0000000000000000000000000000000000000000-0"
When executing in UNBLOCKING mode, the engine replies with an Execution ID that represents the function’s execution internally. The execution IDs are unique. They are made of two parts, a shard identifier and a sequence, delimited by a hyphen (‘-‘). The shard identifier is unique for each shard in a Redis Cluster, whereas the sequence is incremented each time the engine executes a function.
By calling the RG.DUMPEXECUTIONS command, we can fetch the engine’s executions list, which currently has just one entry representing the function we’ve just run:
1
2
3
4
5
6
$ redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -c RG.DUMPEXECUTIONS
1) 1) "executionId"
2) "0000000000000000000000000000000000000000-0"
3) "status"
4) "done"
Because the function’s execution is finished, as indicated by the value done in the status field, we can now obtain its execution results with the RG.GETRESULTS command. As the name suggests, the command returns the results of the execution specified by its ID:
1
2
3
4
5
6
7
$ redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -c RG.GETRESULTS 0000000000000000000000000000000000000000-0
1) 1)"['age', '35', 'fname', 'Beth', 'lname', 'Smith']"
2)"['age', '70', 'fname', 'Rick', 'lname', 'Sanchez']"
3)"['age', '87', 'fname', 'Shrimply', 'lname', 'Pibbles']"
4)"['age', '14', 'fname', 'Morty', 'lname', 'Smith']"
5)"['age', '17', 'fname', 'Summer', 'lname', 'Smith']"
Before the done status, the engine would have replied with an error.
Observe that we got the collected results (persons) in a different order than they were created. This is because the originating shard mapped the function to all other shards and then collected the intermediate local results before returning a merged response.
Before returning the results, the coordinator of the originating shard collects the local results from each shard. This is the default behavior, and using it implicitly adds a collect() operation to the function as its last step.
Although data is distributed across the cluster’s shards, the function returns identical (order excluded) results to what a single-instance would have returned. This is because the originating shard had distributed (mapped) the function to the cluster shards and then collected the intermediate local results from all other shards before returning a merged response. This concept is known as MapReduce.

4 - RedisGears: Stream processing
Until this point, we’ve executed batch functions, which means that we’ve used the run() action to have the function execute immediately. When executed this way, the function’s reader fetches whatever data exists and then stops. Once the reader stops, the function is finished, and its results are returned.
In many cases, data constantly changes and needs to be processed in an event-driven manner. For that purpose, RedisGears functions can be registered as triggers that “fire” on specific events to implement what is known as stream processing flows. A registered function’s reader doesn’t read existing data but waits for new input to trigger steps instead.
The function is executed once for each new input record as a default when registered to process streaming data. However, whereas batch functions are executed exactly once, a registered function’s execution may be triggered any number of times in response to the events that drive it.
To try this, we’ll return the person hashes with names split into two fields, as seen earlier. But instead of running it in batch, we register() it for incoming persons:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def split_name(key):
person_name = execute("HGET", key, "name")
first_name = person_name.split(' ')[0]
last_name = person_name.split(' ')[1]
execute("HMSET", key, "fname", first_name, "lname", last_name)
execute("HDEL", key, "name")
return execute("HGETALL", key)
GearsBuilder()\
.map(lambda x: x['key'])\
.map(split_name)\
.collect()\
.register("person:*")
## Expected result: ['OK']
Let’s add a new person:
HSET person:6 name "Amine El-Kouhen" age 36
Now, as soon as a new person is set into Redis, the function will be executed, and the results can be obtained when the execution status shows done.
1
2
3
4
5
6
7
8
$ redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -c RG.DUMPEXECUTIONS
1) 1) "executionId"
2) "0000000000000000000000000000000000000000-119"
3) "status"
4) "done"
5) "registered"
6) (integer) 1
You can then get the execution results of the execution specified by its ID with the RG.GETRESULTS command:
1
2
3
4
$ redis-cli -h redis-12000.cluster.redis-process.demo.redislabs.com -p 12000 -c RG.GETRESULTS 0000000000000000000000000000000000000000-119
1) 1) "['age', '36', 'fname', 'Amine', 'lname', 'El-Kouhen']"
2) (empty array)
We can use the stream processing with gears to perform aggregate functions that can evolve while data is ingested in Redis. For example, let’s assume that Apple’s financial data are stored in Redis. Stakeholders might have a requirement to see the Profit and Loss statement in real-time.

The Profit and Loss Statement (P&L) is a financial statement that starts with revenue and deducts costs and expenses to arrive at a company’s net income, the profitability of a specified period. Let’s first implement the logic we want to expose for our users:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
def grouping_by_account(x):
return x['value']['account']
def summer(k, a, r):
''' Accumulates the amounts '''
a = execute("GET", k)
a = float(a if a else 0) + float(r['value']['amount'])
execute("SET", k, a)
return a
def create_pnl(a):
if a['key'] == "Revenue":
execute("HSET", "pnl", "total_net_sales", execute("GET", a['key']))
elif a['key'] == "Cost":
execute("HSET", "pnl", "total_cost_sales", execute("GET", a['key']))
elif a['key'] == "Operating Expenses":
execute("HSET", "pnl", "operating_expenses", execute("GET", a['key']))
elif a['key'] == "Provision":
execute("HSET", "pnl", "provision", execute("GET", a['key']))
def get_value_or_zero(field):
r = execute("HGET", "pnl", field)
return float(r) if r else 0
def consolidate_pnl(a):
gross_margin = get_value_or_zero("total_net_sales") - get_value_or_zero("total_cost_sales")
operating_income = get_value_or_zero("gross_margin") - get_value_or_zero("operating_expenses")
net_income = get_value_or_zero("operating_income") - get_value_or_zero("provision")
execute("HSET", "pnl", "gross_margin", gross_margin)
execute("HSET", "pnl", "operating_income", operating_income)
execute("HSET", "pnl", "net_income", net_income)
gb = GearsBuilder()
gb.groupby(grouping_by_account, summer)
gb.map(create_pnl)
gb.map(consolidate_pnl)
gb.register('record:*')
In this Gears function, we’ve introduced the groupby() operation. It performs the grouping of records according to grouping criteria and can perform aggregation by the grouping elements. Here the function makes a sum of all records grouped by an accounting nature (e.g., Revenue, Cost, etc.)
Once the grouping is performed, the function creates a pnl hash that contains the calculation of the entries that compose the P&L statement and consolidates them to calculate the net income.
As you can observe, this function is an event-triggered procedure (aka. registered). That means it will be executed once a financial record is set into Redis. This way, end users can derive real-time insights about the company’s financial condition with less effort.
Let’s execute these commands to create new financial records. To simplify the example, each financial transaction consists only of an accounting nature and the transaction amount:
1
2
3
4
5
6
7
HSET record:1 account "Revenue" amount 316199
HSET record:2 account "Revenue" amount 78129
HSET record:3 account "Cost" amount 201471
HSET record:4 account "Cost" amount 22075
HSET record:5 account "Operating Expenses" amount 26251
HSET record:6 account "Operating Expenses" amount 25094
HSET record:7 account "Provision" amount 19300
Assuming all records are actual transactions, stakeholders can get the company’s financial situation in real-time, and the different revenues and expenses get updated continuously.
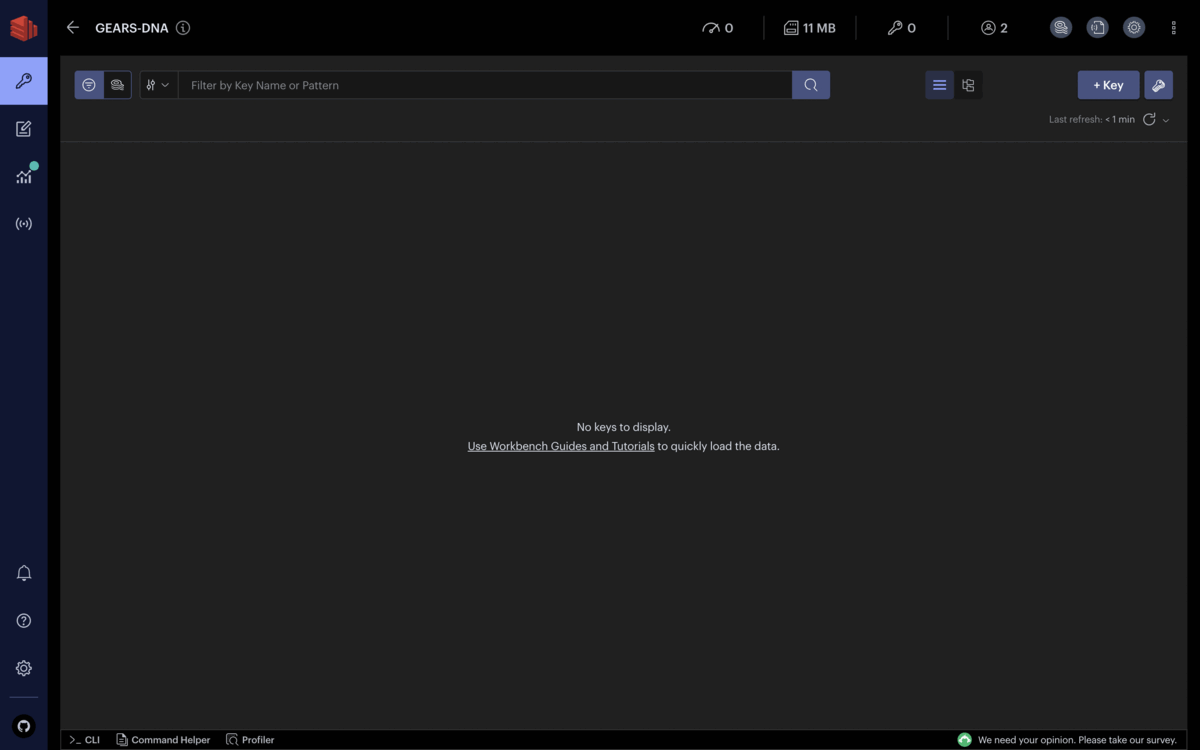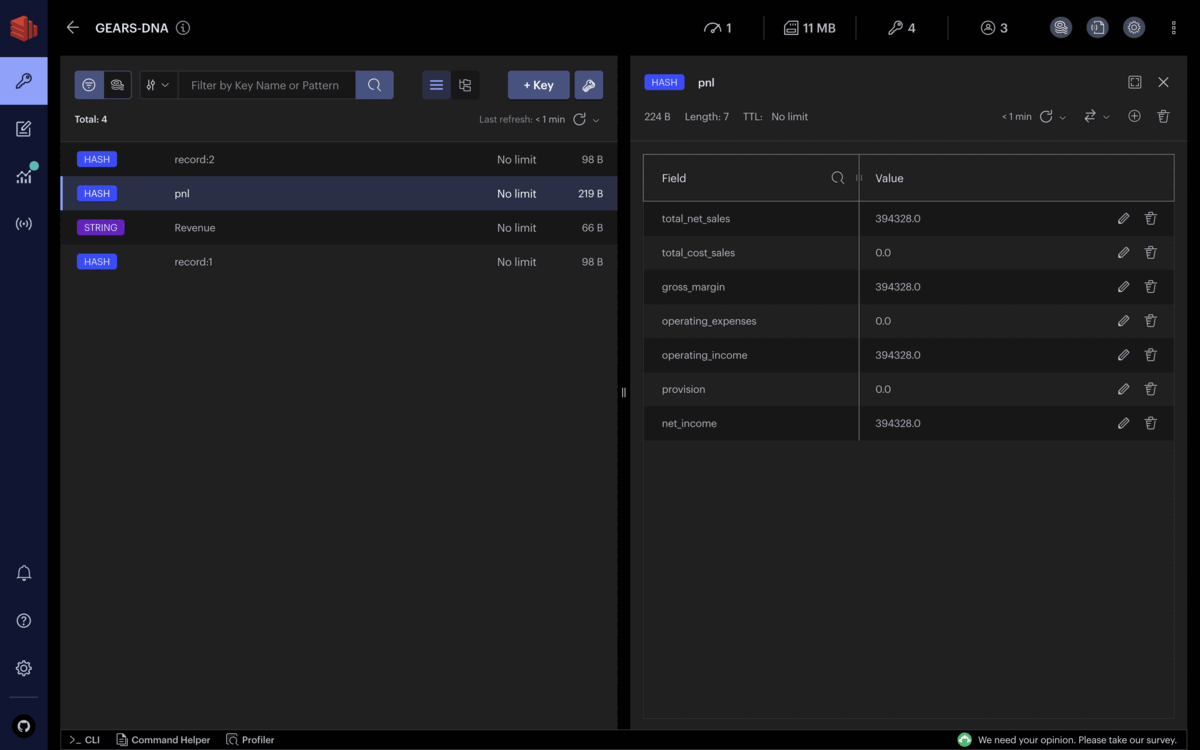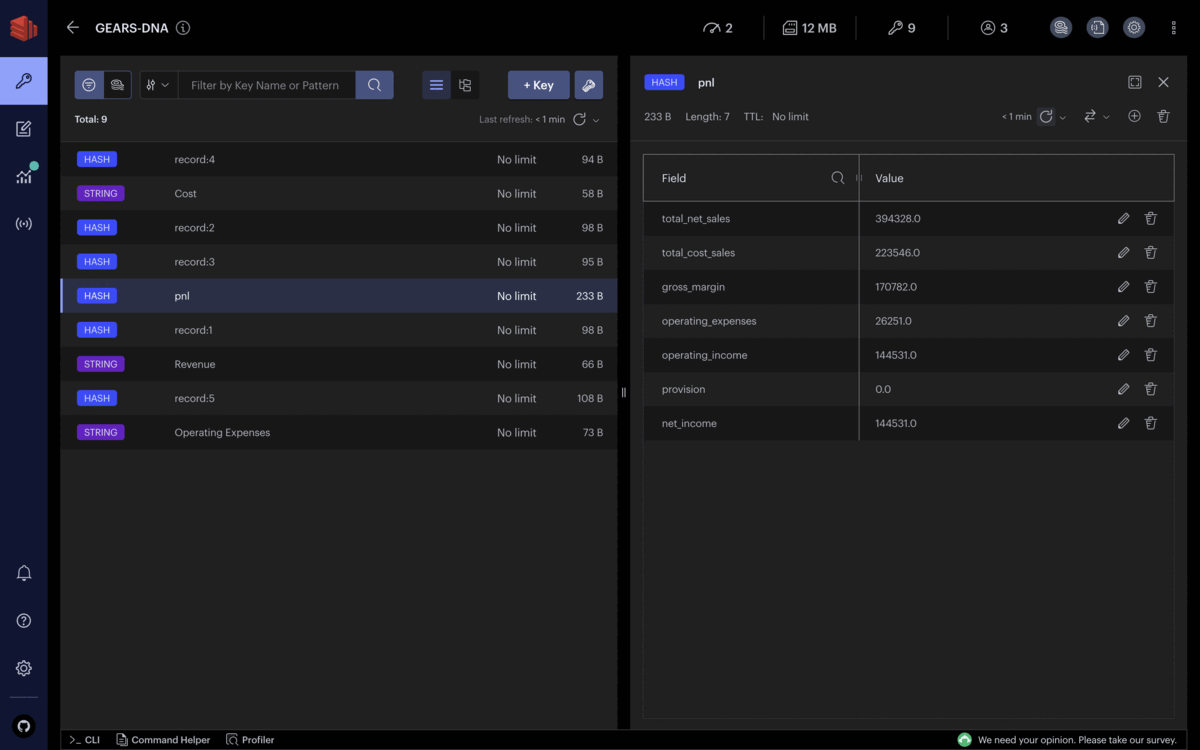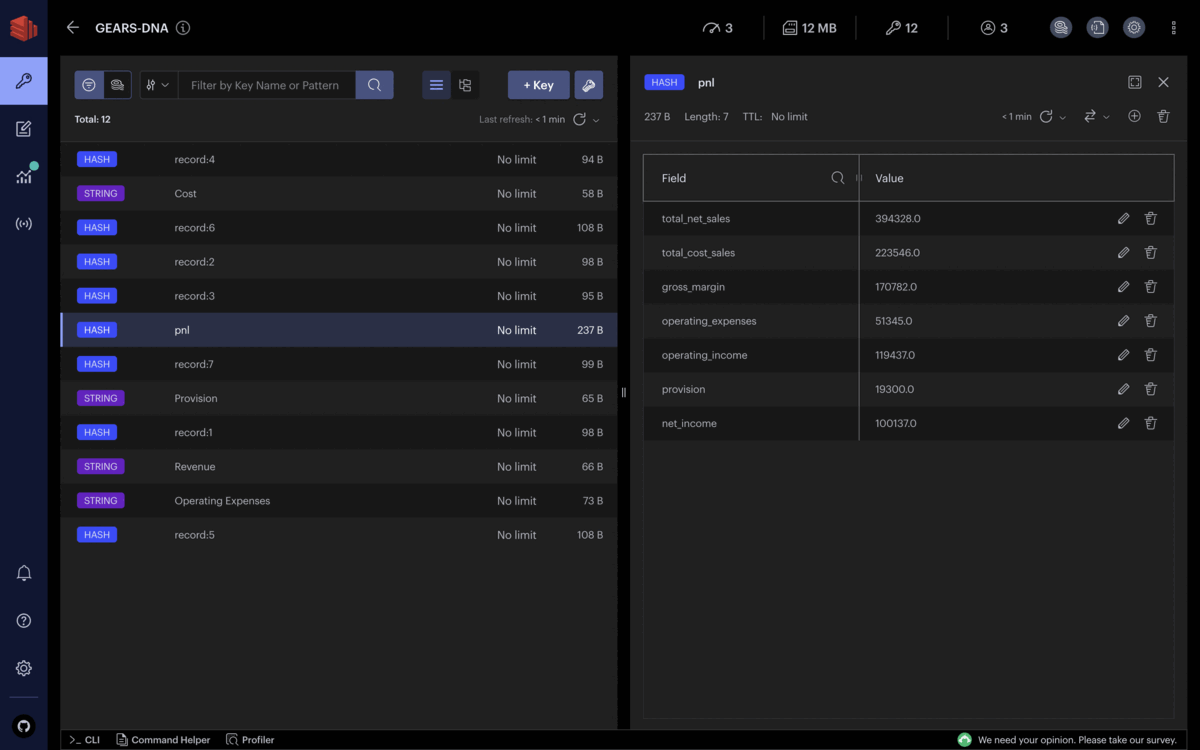
Each financial record added to Redis is immediately captured, grouped by the accounting nature, and entered in the calculation of the main lines of the profit and loss statement. You can observe that the net income evolves as often as financial records keep entering Redis.
Summary
In this post, we tested the data processing engine of Redis called RedisGears. It supports transaction, batch, and event-driven processing of Redis data through functions that describe how data should be processed.
We’ve seen how RedisGears process data in a batch fashion using the run block and how RedisGears functions can be triggered to process a data stream by registering functions beforehand. In version 2.0 (still under development), RedisGears allows running JavaScript functions by API calls, time-triggering, and keyspace triggering, which we tested in the stream processing section, thus offering a better end-user experience than the current version.
Moreover, in the future version of RedisGears, the functions will be considered an integral part of the database (first-class artifacts of the database). Thus, Redis ensures their availability via data persistence and replication.
References
- Redis Gears, Developer Guide