“Data & Redis” is a series that introduces Redis as a real-time data platform. Through this series, you will learn how to collect, store, process, analyze, and expose data in real time using a wide variety of tools provided by Redis. Redis is an open-source, in-memory data store used as a database, cache, streaming engine, and message broker. It supports various data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. In addition, Redis provides a sub-millisecond latency with very high throughput: up to 200M Ops/sec at a sub-millisecond scale, which makes it the obvious choice for real-time use cases.
In this article, I will illustrate data ingestion and integration using Redis and the myriad of tools it provides. As you’ve seen earlier, Data ingestion is the first stage of the data lifecycle. This is where data is collected from various internal sources like databases, CRM, ERPs, legacy systems, external ones such as surveys, and third-party providers. This is an important step because it ensures the good working of subsequent stages in the data lifecycle.
In this stage, raw data are extracted from one or more data sources, replicated, then ingested into a landing storage support, Redis for instance. We’ve seen that most ingestion tools can handle a high volume of data with a wide range of formats (structured, unstructured…), but they differ in how they handle the data velocity. We often distinguish three main categories of data ingestion tools: batch-based, real-time or stream-based, and hybrid ingestion. With Redis, we will see the different data ingestion tools that form the Redis ecosystem and how they can address the different categories of data ingestion.
Pre-requisites
1 - Create a Redis Database
You need to install and set up a few things for this article. First, you must prepare the landing storage support that can be a Redis open-source (OSS) or a Redis Enterprise Cluster. This storage support will be the target infrastructure for the data acquired in this stage. You can install Redis OSS by following the instructions here, or you can use this project to create a Redis Enterprise cluster in the cloud provider of your choice.
Once you have created a Redis Enterprise cluster, you have to create a target database that holds the ingested data. Redis Enterprise Software lets you create and distribute databases across a cluster of nodes. To create a new database, follow the instructions here. For the rest of the article, we assume that for RIOT, you use a database with the endpoint: redis-12000.cluster.redis-ingest.demo.redislabs.com:12000. For Redis Data Integration, you need two databases: the config database exposed on redis-13000.cluster.redis-ingest.demo.redislabs.com:13000 and the target database on: redis-14000.cluster.redis-ingest.demo.redislabs.com:14000
2 - Install RIOT tools
Now, let’s install the RIOT-File tool.
RIOT-File can be installed in different ways depending on your environment and preference. If you want to install it on MacOS, you can use Homebrew with the command:
brew install redis-developer/tap/riot-file
You can also download the latest release, unzip it, and copy it to the desired location. Then launch the bin/riot-file script.
Or, you can simply run the latest docker image:
docker run fieldengineering/riot-file [OPTIONS] [COMMAND]
Then, you need to install the RIOT-DB tool using Homebrew on MacOS:
brew install redis-developer/tap/riot-db
Or, by running the latest docker image:
docker run fieldengineering/riot-db [OPTIONS] [COMMAND]
3 - Install Redis Data Integration (RDI)
For the second part of this article, you will need to install Redis Data Integration (RDI). Redis Data Integration installation is done via the RDI CLI. The CLI should have network access to the Redis Enterprise cluster API (port 9443 by default). You need first to download the RDI offline package :
UBUNTU20.04
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-ubuntu20.04-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
UBUNTU18.04
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-ubuntu18.04-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
RHEL8
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-rhel8-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
RHEL7
wget https://qa-onprem.s3.amazonaws.com/redis-di/latest/redis-di-offline-rhel7-latest.tar.gz -O /tmp/redis-di-offline.tar.gz
Then Copy and unpack the downloaded redis-di-offline.tar.gz into the master node of your Redis Cluster under the /tmp directory:
1
tar xvf /tmp/redis-di-offline.tar.gz -C /tmp
Switch the current user to the user with whom the cluster was created (usually redislabs or ubuntu). Install RedisGears on the cluster. In case it’s missing, follow this guide to install it.
1
2
curl -s https://redismodules.s3.amazonaws.com/redisgears/redisgears.Linux-ubuntu20.04-x86_64.1.2.5.zip -o /tmp/redis-gears.zip
curl -v -k -s -u "<REDIS_CLUSTER_USER>:<REDIS_CLUSTER_PASSWORD>" -F "module=@/tmp/redis-gears.zip" https://<REDIS_CLUSTER_HOST>:9443/v2/modules
Then you install the RDI CLI by unpacking redis-di.tar.gz into /usr/local/bin/ directory:
sudo tar xvf /tmp/redis-di-offline/redis-di-cli/redis-di.tar.gz -C /usr/local/bin/
Run the create command to set up a new Redis Data Integration database instance within an existing Redis Enterprise Cluster. This database is different from the target database that holds the transformed data. The RDI database is a small data store that holds only configurations and statistics about processed data. Let’s create one and expose it in port 13000:
redis-di create --silent --cluster-host <CLUSTER_HOST> --cluster-user <CLUSTER_USER> --cluster-password <CLUSTER_PASSWORD> --rdi-port <RDI_PORT> --rdi-password <RDI_PASSWORD> --rdi-memory 512
Finally, run the scaffold command to generate configuration files for Redis Data Integration and Debezium Redis Sink Connector:
redis-di scaffold --db-type <cassandra|mysql|oracle|postgresql|sqlserver> --dir <PATH_TO_DIR>
In this article, we will capture a SQL Server database, so choose (sqlserver). The following files will be created in the provided directory:
├── debezium
│ └── application.properties
├── jobs
│ └── README.md
└── config.yaml
config.yaml- Redis Data Integration configuration file (definitions of the target database, applier, etc.)debezium/application.properties- Debezium Server configuration filejobs- Data transformation jobs, read here
To use debezium as a docker container, download the debezium Image:
wget https://qa-onprem.s3.amazonaws.com/redis-di/debezium/debezium_server_2.1.1.Final_offline.tar.gz -O /tmp/debezium_server.tar.gz
and load it as a docker image. Make sure that you already have docker installed in your machine.
docker load < /tmp/debezium_server.tar.gz
Then tag the image:
1
2
docker tag debezium/server:2.1.1.Final_offline debezium/server:2.1.1.Final
docker tag debezium/server:2.1.1.Final_offline debezium/server:latest
For the non-containerized deployment, you need to install Java 11 or Java 17. Then download Debezium Server 2.1.1.Final from here.
Unpack Debezium Server:
tar xvfz debezium-server-dist-2.1.1.Final.tar.gz
Copy the scaffolded application.properties file (created by the scaffold command) to the extracted debezium-server/conf directory. Verify that you’ve configured this file based on these instructions.
If you use Oracle as your source DB, please note that Debezium Server does not include the Oracle JDBC driver. You should download it and locate it under debezium-server/lib directory:
1
2
cd debezium-server/lib
wget https://repo1.maven.org/maven2/com/oracle/database/jdbc/ojdbc8/21.1.0.0/ojdbc8-21.1.0.0.jar
Then, start Debezium Server from debezium-server directory:
./run.sh
Batch Ingestion using RIOT
Batch ingestion is the process of collecting and transferring data in batches according to scheduled intervals. Redis Input/Output Tools (RIOT) is a series of utilities designed to help you get data in and out of Redis in a batch fashion. It consists of several modules that can ingest data from files (RIOT-File) or relational databases to Redis (RIOT-DB). It can also migrate data from/to Redis (RIOT-Redis). RIOT supports Redis open-source (OSS) and Redis Enterprise in either standalone or cluster deployments.
The RIOT tool reads a fixed number of records (batch chunks), processes them, and writes it at a time. Then the cycle is repeated until no more data on the source exists. The default batch size is 50, which means that an execution step reads 50 items at a time from the source, processes them, and finally writes them to the target. If the target is Redis, writing is done in a single command pipeline to minimize the number of roundtrips to the server. You can change the batch size (and hence pipeline size) using the --batch option. The optimal batch size for throughput depends on a few factors, like record size and command types (see here for details).
RIOT can implement processors to perform custom transformations to the ingested data and apply filters based on regular expressions before writing data in the landing storage support.
It is possible to parallelize processing using multiple threads using the --threads option. In that configuration, each chunk of items is read, processed, and written in a separate thread of execution. This differs from partitioning, where multiple readers would read items (see Redis Data Integration). Here, only one reader is accessed from multiple threads.

1 - Flat files ingestion using RIOT-File
RIOT-File provides commands to read from files and write to Redis. It supports various file formats as delimited flat files: CSV, TSV, PSV, or fixed-width files. RIOT-File can also import files in JSON or XML formats.
To ingest data from flat files to a Redis database, you need to execute the import command:
riot-file -h <host> -p <port> import FILE... [REDIS COMMAND...]
The import command reads from files and writes to Redis. The file paths can be absolute or in a URL form. In addition, paths can include wildcard patterns (e.g., file_*.csv). Using the object URL, you can also ingest objects from AWS S3 or GCP storage service.
RIOT-File will try to determine the file type from its extension (e.g., .csv or .json), but you can specify it explicitly using the --filetype option.
For flat file formats (delimited and fixed-length), you can use the --header option to automatically extract field names from the file’s first row. Otherwise, you can specify the field names using the –fields option.
The default delimiter character is a comma (,). However, it can be customized by using the --delimiter option.
Let’s consider this CSV file:
| AirportID | Name | City | Country | IATA | ICAO | Latitude | Longitude | Altitude | Timezone | DST | Tz | Type | Source |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Goroka Airport | Goroka | Papua New Guinea | GKA | AYGA | -6.081689834590001 | 145.391998291 | 5282 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 2 | Madang Airport | Madang | Papua New Guinea | MAG | AYMD | -5.20707988739 | 145.789001465 | 20 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 3 | Mount Hagen Kagamuga Airport | Mount Hagen | Papua New Guinea | HGU | AYMH | -5.826789855957031 | 144.29600524902344 | 5388 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 4 | Nadzab Airport | Nadzab | Papua New Guinea | LAE | AYNZ | -6.569803 | 146.725977 | 239 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 5 | Port Moresby Jacksons International Airport | Port Moresby | Papua New Guinea | POM | AYPY | -9.443380355834961 | 147.22000122070312 | 146 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
| 6 | Wewak International Airport | Wewak | Papua New Guinea | WWK | AYWK | -3.58383011818 | 143.669006348 | 19 | 10 | U | Pacific/Port_Moresby | airport | OurAirports |
The following command imports that CSV file into Redis as a JSON object with airport as the key prefix and AirportID as the primary key.
riot-file -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/airport.csv --header json.set --keyspace airport --keys AirportID

You can observe that the CSV file contains geographical coordinates (longitudes and latitudes). You can thus leverage the Redis geospatial indexes that let you store coordinates and search for them. This data structure is useful for finding nearby points within a given radius or bounding box. For example, this command imports the CSV file into a geo set named airportgeo with AirportID as a member:
riot-file -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/airport.csv --header geoadd --keyspace airportgeo --members AirportID --lon Longitude --lat Latitude
You can use a regular expression to extract patterns from source fields and keep only records matching a SpEL boolean expression. For example, this filter will only keep Canadian Airports. Aka. where the Country field matches Canada.
riot-file -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/airport.csv --header --filter "Country matches 'Canada'" hset --keyspace airport:canada --keys AirportID

You can also make transformations while ingesting data using RIOT. This feature allows you to create/update/delete fields using the Spring Expression Language (SpEL). For example, you can add a new field by using field1='foo', you can standardize a field values to convert temperature from Fahrenheit to Celsius temp=(temp-32)*5/9, you can merge two fields into one and delete the old fields name=remove(first).concat(remove(last)), or you can simply delete the fields that you wont use (e.g., field2=null).
The transform processor also exposes functions and variables that can be accessed using the # prefix, like the date parser #date, get the sequence number of the item being generated with #index, and you can invoke Redis commands by using #redis.
2 - Relational tables ingestion using RIOT-DB
RIOT-DB includes several JDBC drivers to read from the most common RDBMSs (Oracle, IBM DB2, SQL Server, MySQL, PostgreSQL, and SQLite). Moreover, RIOT-DB is extensible; it can read from other databases by adding their corresponding JDBC drivers under the lib directory of the tool.
To ingest data from relational databases to a Redis database, you need to execute the import command:
riot-db -h <host> -p <port> import --url <jdbc url> SQL [REDIS COMMAND...]
The import command reads from the RDBMS tables using SQL queries and writes to Redis. The --url option specifies the JDBC connection string to the source database, and the SQL query sets the table and the filtering condition on the source side. You can also use SQL aggregation functions to process and return transformed fields. You can also use the RIOT processors (similar to RIOT-File) to perform transforms and the filtering logic on the RIOT side.
Let’s consider a MySQL database containing three tables, one for the continents, another for the world’s countries, and the last containing the currencies.
Assuming that the database’s endpoint is riot-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com:3306, the following command imports the countries table into Redis as hashes using the country as the key prefix and code as the primary key.
riot-db -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import "SELECT * FROM countries" --url "jdbc:mysql://riot-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com:3306/geography" --username admin --password riot-password hset --keyspace country --keys code

The main advantage of using SQL queries in the load is the ability to make custom structures that join multiple tables and filter regarding a specific field. For example, the following command only imports the African countries with the full currency name of each country. The result is ingested into Redis as JSON objects using africa as the key prefix and code as the primary key.
riot-db -h redis-12000.cluster.redis-ingest.demo.redislabs.com -p 12000 import "SELECT countries.code, countries.name, countries.capital, continents.continent_name, currencies.currency_name FROM countries JOIN continents on countries.continent_code = continents.continent_code JOIN currencies on countries.currency = currencies.currency_code WHERE continents.continent_name like 'Africa'" --url "jdbc:mysql://riot-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com:3306/geography" --username admin --password riot-password json.set --keyspace africa --keys code

Stream Ingestion using Redis Data Integration (RDI)
Real-time or Stream-based ingestion is essential for organizations to rapidly respond to new information in time-sensitive use cases, such as stock market trading or sensors monitoring. Real-time data acquisition is vital when making rapid operational decisions or acting on fresh insights.
Redis Data Integration (RDI) is a product that helps Redis Enterprise users to ingest and export data in near real-time so that Redis becomes part of their data fabric with no extra integration efforts. RDI can mirror several kinds of databases to Redis using the Capture Data Change (CDC) concept. The CDC constantly monitors the database transaction logs and moves changed data as a stream without interfering with the database workload. Redis Data Integration is a data ingestion tool that collects the list of events that changed an OLTP system data over a given period and writes it into Redis Enterprise.
In OLTP (Online Transaction Processing) systems, data is accessed and changed concurrently by multiple transactions, and the database changes from one consistent state to another. An OLTP system always shows your data’s latest state, facilitating the workloads that require near real-time data consistency guarantees. All these database states are kept in the transaction log (aka. redo log or Write-Ahead Log), which stores row-based modifications.
Therefore, to capture changes in a relational database, you just need to scan the transaction log and extract the change events from it. Historically, each RDBMS used its own way of decoding the underlying transaction log:
- Oracle offers GoldenGate (LogMiner)
- SQL Server offers built-in support for CDC
- PostgreSQL with its Write-Ahead Log (WAL)
- MySQL, which exposes a binary log (BinLog) that can be captured using various 3rd party solutions, like LinkedIn’s DataBus.
But there’s a new tool here! Debezium is a new open-source project developed by RedHat, which offers connectors for Oracle, MySQL, PostgreSQL, and even MongoDB. Debezium provides a Redis Sink Connector that feeds Redis Data Integration (RDI). Because it doesn’t only extract CDC events but can propagate them to RedisStreams1, which acts as a backbone for all the messages that need to be exchanged between various stages of data architecture.

With Redis Data Integration (RDI), Data is extracted from the source database using Debezium connectors. Data is then loaded into a Redis DB instance that keeps the data in RedisStreams alongside the required metadata. Data can then be transformed using RedisGears recipes recipes or Apache Spark using the Spark-Redis connector.
Redis Data Integration (RDI) can be considered a hybrid data ingestion tool as it performs an initial sync - where a snapshot of the entire database or a subset of selected tables is used as a baseline. Then, the entire data is ingested as a batch chunk streamed to Redis Data Integration and then transformed and written into the target Redis DB. Then, It performs the live capture - where data changes that happen after the baseline snapshot are captured and streamed to Redis Data Integration, where they are transformed and written to the target.
Let’s consider an SQL Server database FO (Financial & Operations) that contains a general ledger table. A general ledger represents the record-keeping system for a company’s financial data, with debit and credit account records. It provides a record of each financial transaction that takes place during the life of an operating company and holds account information needed to prepare the company’s financial statements.
| ID | JOURNALNUM | SPLTRMAGSUM | AMOUNTMSTSECOND | TAXREFID | DIMENSION6_ | SPL_JOBNUMBER | SPL_JOBDATE | JOURNALIZESEQNUM | CREATEDTRANSACTIONID | DEL_CREATEDTIME | DIMENSION | QTY | POSTING | OPERATIONSTAX | DIMENSION4_ | REASONREFRECID | DIMENSION2_ | DATAAREAID | CREATEDBY | SPL_LEDGERACCMIRRORING_TR | TRANSTYPE | DOCUMENTDATE | TRANSDATE | MODIFIEDBY | CREDITING | SPL_BALANCINGID | BONDBATCHTRANS_RU | RECID | MODIFIEDDATETIME | AMOUNTCUR | CURRENCYCODE | RECVERSION | CORRECT | ACCOUNTNUM | AMOUNTMST | CREATEDDATETIME | PERIODCODE | ALLOCATELEVEL | FURTHERPOSTINGTYPE | DIMENSION5_ | VOUCHER | DIMENSION3_ | ACKNOWLEDGEMENTDATE | EUROTRIANGULATION |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | GJN0055555 | 0 | 0.000000000000 | 0 | 8385 | NULL | 1900-01-01 00:00:00.0000000 | 0 | 5664245147 | 48243 | NL03PC301 | 0.000000000000 | 31 | 0 | x | 0 | x | nl03 | ronal | 0 | 15 | 1900-01-01 00:00:00.0000000 | 2020-11-02 00:00:00.0000000 | ronal | 1 | 0 | 0 | 5733875370 | 2020-11-03 12:24:03.0000000 | -1.773.990.000.000.000 | EUR | 1 | 0 | 240100 | -1.773.990.000.000.000 | 2020-11-03 12:24:03.0000000 | 1 | 0 | 0 | x | RPM000134685 | x | 2020-11-02 00:00:00.0000000 | 0 |
| 2 | GJN0154431 | 0 | 0.000000000000 | 0 | 90000211 | SSHAS639739 | 1900-01-01 00:00:00.0000000 | 0 | 5664300488 | 50808 | IT08PC330 | 0.000000000000 | 14 | 0 | MARI | 0 | 34230 | IT08 | arian | 0 | 0 | 2020-11-30 00:00:00.0000000 | 2020-11-30 00:00:00.0000000 | arian | 0 | 0 | 0 | 5734845976 | 2020-12-02 13:06:48.0000000 | 521.550.000.000.000 | EUR | 1 | 0 | 732000 | 521.550.000.000.000 | 2020-12-02 13:06:48.0000000 | 1 | 0 | 0 | GENCAR | GOI20000050977 | MISC | 2020-11-30 00:00:00.0000000 | 0 |
| 3 | GJN0055690 | 0 | 0.000000000000 | 0 | NLNEVATRHGV | NULL | 1900-01-01 00:00:00.0000000 | 0 | 5664258998 | 38650 | NL03PC301 | 0.000000000000 | 41 | 0 | x | 0 | x | nl03 | vanja | 0 | 15 | 1900-01-01 00:00:00.0000000 | 2020-11-13 00:00:00.0000000 | vanja | 0 | 0 | 0 | 5734092101 | 2020-11-11 09:44:10.0000000 | 2.667.090.000.000.000 | EUR | 1 | 0 | 260100 | 2.667.090.000.000.000 | 2020-11-11 09:44:10.0000000 | 1 | 0 | 0 | x | PPM000086183 | x | 2020-11-13 00:00:00.0000000 | 0 |
| 4 | GJN0152885 | 0 | 0.000000000000 | 1 | ITPOGRPML | SNGBS235260 | 2020-09-21 00:00:00.0000000 | 0 | 5664261485 | 42195 | IT08PC330 | 0.000000000000 | 14 | 0 | MARI | 0 | 34230 | it08 | gius1 | 0 | 0 | 2020-11-11 00:00:00.0000000 | 2020-11-11 00:00:00.0000000 | gius1 | 1 | 0 | 0 | 5734121975 | 2020-11-12 10:43:15.0000000 | -188.550.000.000.000 | EUR | 1 | 0 | 801100 | -188.550.000.000.000 | 2020-11-12 10:43:15.0000000 | 1 | 0 | 0 | GENCAR | RTI20000049694 | MISC | 2020-11-11 00:00:00.0000000 | 0 |
| 5 | GJN0152220 | 0 | 0.000000000000 | 0 | ITESAOTEFLR | SHKGA176733 | 1900-01-01 00:00:00.0000000 | 0 | 5664242642 | 18523 | IT08PC331 | 0.000000000000 | 14 | 0 | x | 0 | x | it08 | arian | 0 | 0 | 1900-01-01 00:00:00.0000000 | 2020-11-01 00:00:00.0000000 | arian | 1 | 0 | 0 | 5733849435 | 2020-11-03 04:08:43.0000000 | -56.690.000.000.000 | EUR | 1 | 0 | 245000 | -56.690.000.000.000 | 2020-11-03 04:08:43.0000000 | 1 | 0 | 0 | x | GOI20000037656 | x | 2020-11-01 00:00:00.0000000 | 0 |
We will configure Debezium and Redis-DI to capture and collect any change in this general ledger table. It means that every new transaction or an update on an old transaction will be captured and identified in near real-time. This scenario is often used for organizations that need to make operational decisions based on fresh observations. We assume that the source database’s endpoint is: rdi-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com:1433
1 - SQL Server configuration
To use the Debezium SQL Server connector, it is a good practice to have a dedicated user with the minimal required permissions in SQL Server to control blast radius. For that, you need to run the T-SQL script below:
1
2
3
4
5
6
7
8
USE master
GO
CREATE LOGIN dbzuser WITH PASSWORD = 'dbz-password'
GO
USE FO
GO
CREATE USER dbzuser FOR LOGIN dbzuser
GO
And Grant the Required Permissions to the new User
1
2
3
4
USE FO
GO
EXEC sp_addrolemember N'db_datareader', N'dbzuser'
GO
Then you must enable Change Data Capture (CDC) for the database and each table you want to capture.
1
2
EXEC msdb.dbo.rds_cdc_enable_db 'FO'
GO
Run this T-SQL script for each table in the database and substitute the table name in @source_name:
1
2
3
4
5
6
7
8
USE FO
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'GeneralLedger',
@role_name = N'db_cdc',
@supports_net_changes = 0
GO
Finally, the Debezium user created earlier (dbzuser) needs access to the captured change data, so it must be added to the role created in the previous step
1
2
3
4
USE FO
GO
EXEC sp_addrolemember N'db_cdc', N'dbzuser'
GO
You can verify access by running this T-SQL script as user dbzuser:
1
2
3
4
USE FO
GO
EXEC sys.sp_cdc_help_change_data_capture
GO
2 - Redis-DI Configuration
The RDI scaffold command also generated a file called config.yaml. This file holds the connection details of the target Redis instance and Applier settings. So now, it is the turn of Redis-DI to be configured.
In the Redis Data Integration configuration file config.yaml, you need to update the connection/target details to match the target database settings.
1
2
3
4
5
6
connections:
target:
host: redis-14000.cluster.redis-ingest.demo.redislabs.com
port: 14000
user: default
password: rdi-password

Run the deploy command to deploy the local configuration to the remote RDI database:
redis-di deploy --rdi-host redis-13000.cluster.redis-ingest.demo.redislabs.com --rdi-port 13000 --rdi-password rdi-password
3 - Debezium Server configuration
Now it’s time to configure the Debezium server, installed as described in the pre-requisites. In the configuration file application.properties, you need to set the prefix:
debezium.source.topic.prefix=dna-demo
And the name of your database(s).
debezium.source.database.names=FO
This prefix will be used in the key name of the created objects in the Redis-DI database. The key name is created as data:<topic.prefix>.<database.names>.<schema>.<table_name>
You need to configure the Hostname and port of your SQL Server database.
1
2
debezium.source.database.hostname=rdi-db.cpqlgenz3kvv.eu-west-3.rds.amazonaws.com
debezium.source.database.port=1433
And the Username and password of the Debezium user (dbzuser).
1
2
debezium.source.database.user=dbzuser
debezium.source.database.password=dbz-password
You need to configure the endpoint of your Redis-DI config database and the password.
1
2
debezium.sink.redis.address=redis-13000.cluster.redis-ingest.demo.redislabs.com:13000
debezium.sink.redis.password=rdi-password
All other entries in the file created through the RDI scaffold command can be left at their default values.

Change directory to your Redis Data Integration configuration folder created by the scaffold command, then run:
docker run -d --name debezium --network=host --restart always -v $PWD/debezium:/debezium/conf --log-driver local --log-opt max-size=100m --log-opt max-file=4 --log-opt mode=non-blocking debezium/server:2.1.1.Final
Check the Debezium Server log:
docker logs debezium --follow
When the debezium server is started without errors, Redis Data Integration receives data using RedisStreams. Records with data from the FO database and the GeneralLedger table are written to a stream with a key reflecting the table name data:dna-demo:FO.dbo.GeneralLedger. This allows a simple interface into Redis Data Integration and keeps the order of changes, as observed by Debezium.
Here is the snapshot of the entire GeneralLedger table used as a baseline. The whole table is ingested as a batch chunk streamed to Redis Data Integration and then transformed and written into the target Redis DB.
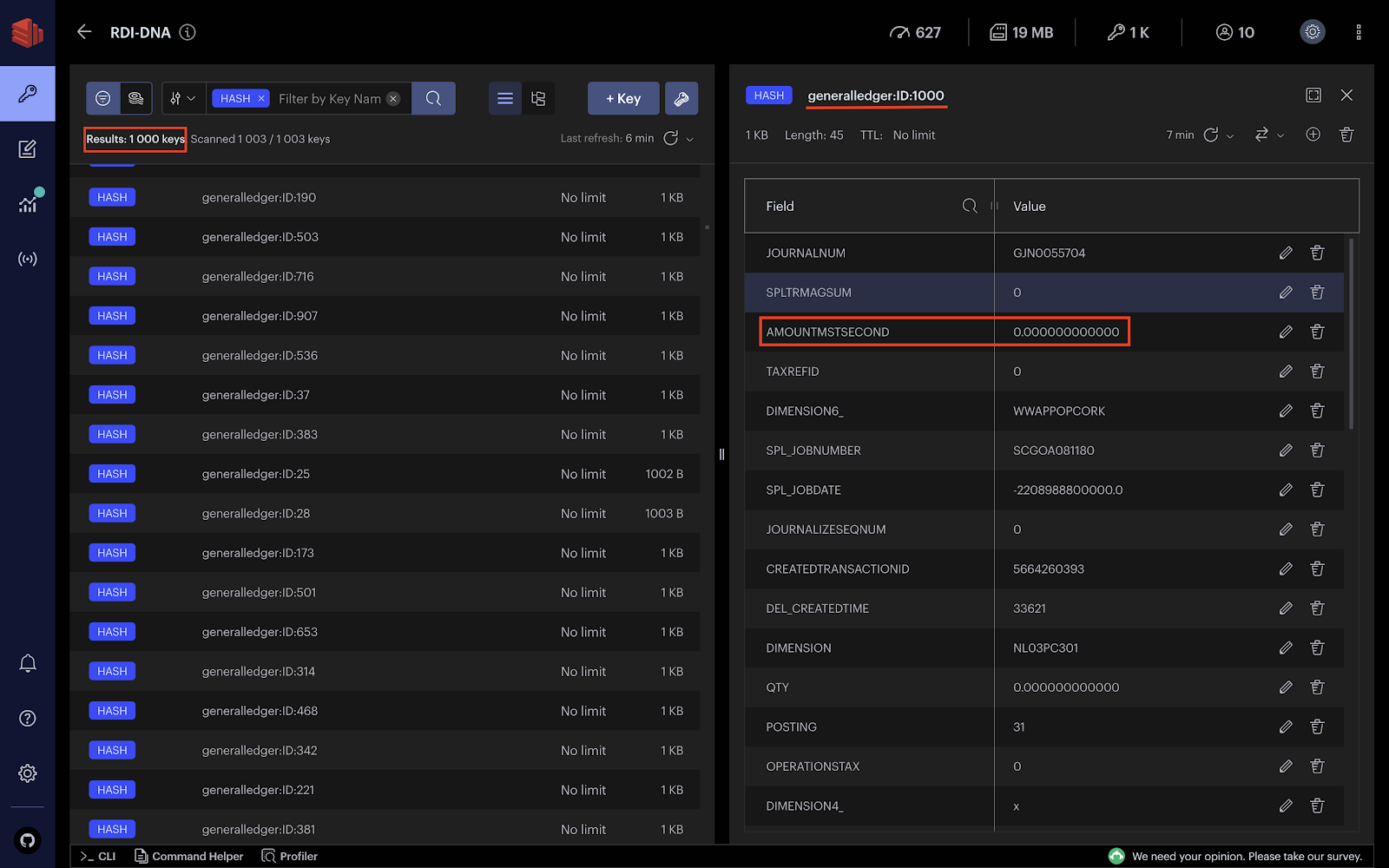
Let’s add two transactions to the general ledger and see how the CDC captures the events on the fly. The following query inserts two transactions into GeneralLedger:
1
2
INSERT INTO dbo.GeneralLedger (JOURNALNUM, SPLTRMAGSUM, AMOUNTMSTSECOND, TAXREFID, DIMENSION6_, SPL_JOBNUMBER, SPL_JOBDATE, JOURNALIZESEQNUM, CREATEDTRANSACTIONID, DEL_CREATEDTIME, DIMENSION, QTY, POSTING, OPERATIONSTAX, DIMENSION4_, REASONREFRECID, DIMENSION2_, DATAAREAID, CREATEDBY, SPL_LEDGERACCMIRRORING_TR, TRANSTYPE, DOCUMENTDATE, TRANSDATE, MODIFIEDBY, CREDITING, SPL_BALANCINGID, BONDBATCHTRANS_RU, RECID, MODIFIEDDATETIME, AMOUNTCUR, CURRENCYCODE, RECVERSION, CORRECT, ACCOUNTNUM, AMOUNTMST, CREATEDDATETIME, PERIODCODE, ALLOCATELEVEL, FURTHERPOSTINGTYPE, DIMENSION5_, VOUCHER, DIMENSION3_, ACKNOWLEDGEMENTDATE, EUROTRIANGULATION) VALUES ('GJN0055897','0','0.000000000000','1','NLANCOMOE','SHKGS177192','1900-01-01 00:00:00.0000000','0','5664282519','34568','NL03PC301','0.000000000000','14','0','MARI','0','34200','nl03','arie.','0','0','2020-11-18 00:00:00.0000000','2020-11-24 00:00:00.0000000','arie.','0','0','0','5734386059','2020-11-25 08:36:08.0000000','1.410.000.000.000.000','EUR','1','0','701100','1.410.000.000.000.000','2020-11-25 08:36:08.0000000','1','0','0','GENCAR','PII000866194','MISC','2020-11-24 00:00:00.0000000','0');
INSERT INTO dbo.GeneralLedger (JOURNALNUM, SPLTRMAGSUM, AMOUNTMSTSECOND, TAXREFID, DIMENSION6_, SPL_JOBNUMBER, SPL_JOBDATE, JOURNALIZESEQNUM, CREATEDTRANSACTIONID, DEL_CREATEDTIME, DIMENSION, QTY, POSTING, OPERATIONSTAX, DIMENSION4_, REASONREFRECID, DIMENSION2_, DATAAREAID, CREATEDBY, SPL_LEDGERACCMIRRORING_TR, TRANSTYPE, DOCUMENTDATE, TRANSDATE, MODIFIEDBY, CREDITING, SPL_BALANCINGID, BONDBATCHTRANS_RU, RECID, MODIFIEDDATETIME, AMOUNTCUR, CURRENCYCODE, RECVERSION, CORRECT, ACCOUNTNUM, AMOUNTMST, CREATEDDATETIME, PERIODCODE, ALLOCATELEVEL, FURTHERPOSTINGTYPE, DIMENSION5_, VOUCHER, DIMENSION3_, ACKNOWLEDGEMENTDATE, EUROTRIANGULATION) VALUES ('GJN0055516','0','0.000000000000','0','NLMEINARN','SRTMS096263','1900-01-01 00:00:00.0000000','0','5664241334','36867','NL03PC301','0.000000000000','14','0','x','0','x','nl03','coos.','0','0','1900-01-01 00:00:00.0000000','2020-11-01 00:00:00.0000000','coos.','1','0','0','5733724085','2020-11-02 09:14:27.0000000','-358.050.000.000.000','EUR','1','0','245000','-358.050.000.000.000','2020-11-02 09:14:27.0000000','1','0','0','x','GOI001629867','x','2020-11-01 00:00:00.0000000','0');

You can observe that debezium captured the two inserts and sent them to the stream data:dna-demo:FO.dbo.GeneralLedger. RedisGears, the data processing engine of Redis, reads the stream entries and creates hashes or JSON objects for each captured row.
The workflow is quite simple. In RDBMSs, the transaction log tracks any DLM command received on the database. Debezium listens and captures changes in the transaction log and fires events to an event streaming system such as RedisStreams. Then RedisGears is notified to consume these events and translates them to Redis data structures (e.g., Hashes or JSON).

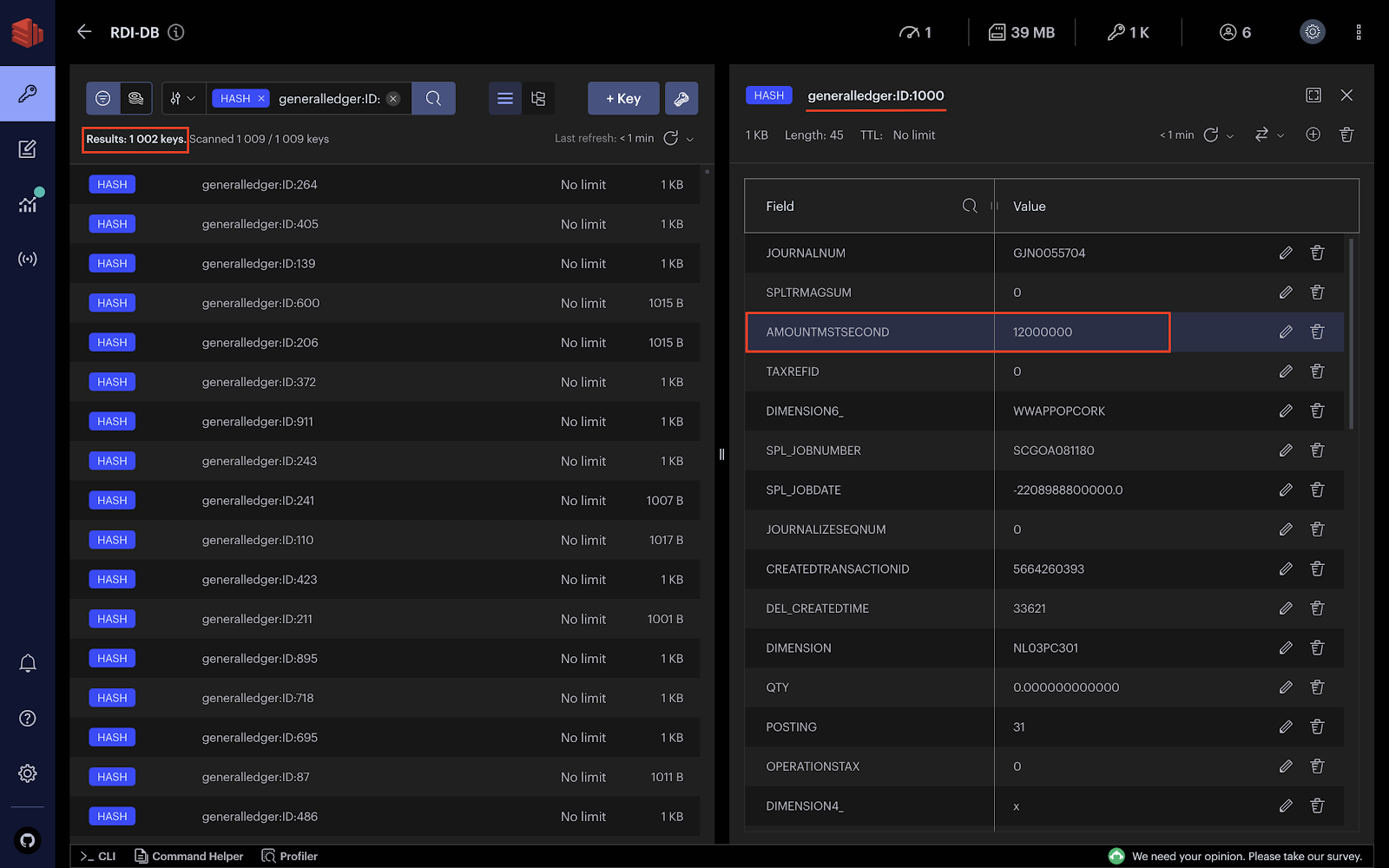
Let’s push it further and update a specific field for a particular row in the GeneralLedger table. For example, the following query updates the field AMOUNTMSTSECOND of the GeneralLedger table for the transaction having the ID equal to 1000.
UPDATE dbo.GeneralLedger SET AMOUNTMSTSECOND = '12000000' WHERE ID = 1000;
When you execute the query, the hash generalledger:ID:1000 should be updated accordingly. You should also observe that you have 1002 keys since we have already inserted two transactions.
Data Integration (RDI), streaming, and Initial Load jobs can be partitioned for linear scalability across single or multiple cluster nodes. For example, table-level data streams can be split into multiple shards where they can be transformed and written to the target in parallel while keeping the table-level order of updates. RDI jobs update their checkpoint upon each committed changed-data event within a transactional scope. When a node failure or a network split occurs, a job would failover to another node and seamlessly begin replication from the last committed checkpoint. Data would not be lost, and order would be maintained.
Redis Data Integration is highly available. At the feeder level, debezium server can be deployed using Kubernetes or Pacemaker for failover between stateless instances while the state is secured in Redis. At the Data and Control Plane, RDI leverages Redis Enterprise mechanisms for high availability (shard replica, cluster level configurations, etc.)
Finally, Redis Data Integration (RDI) allows users to transform their data beyond the default translation of source types to Redis types. The transformations are codeless. You can describe your data transformation in a set of human-readable YAML files, one per source table. Each job describes the transformation logic to perform on data from a single source. The source is typically a database table or collection and is specified as the full name of this table/collection. The job may include a filtering logic to skip data that matches a condition. Other logical steps in the job will transform the data into the desired output to store in Redis (as Hash or JSON). We will dive deep into Redis data processing capabilities in a future article.
Summary
Every data journey starts with data ingestion, either for historical data that can be ingested and processed in a batch fashion or real-time data that need to be collected and transformed on the fly. Redis Enterprise and the set of tools it provides can assist you in building both of these data architectures.
Performing data ingestion using Redis tools can be advantageous since it benefits from Redis’s low latency and high throughput. Redis has a cloud-native and shared-nothing architecture that allows any node to operate stand-alone or as a cluster member. Its platform-agnostic and lightweight design requires minimal infrastructure and avoids complex dependencies on 3rd-party platforms.
In many use cases, historical or referential data that is supposed to be processed too late (with triggered batches) can be ingested using RIOT. Don’t get me wrong. Batch Data are not bad. Several use cases, such as historical reporting and model training (machine learning), work very well with this approach.
However, when you think about your industry, your organization’s needs, and the problems you solve, real-time data may be your choice. Ultimately, real-time data beats slow data for specific use cases when you need to make rapid operational decisions. This statement is always true. Either to increase revenue, reduce cost, reduce risk, or improve the customer experience. For this, Redis Data Integration (RDI) offers, with the help of Debezium, a technical backbone to capture and process data as soon as they are created in the source.
References
- Redis Data Integration (RDI), Developer Guide
- Redis Input/Output Tools (RIOT), RIOT DB - Documentation
- Redis Input/Output Tools (RIOT), RIOT File - Documentation
1. RedisStreams offer up to 500 times the throughput of Apache Kafka at sub-millisecond scale.