“Data & Redis” is a new series that introduces Redis as a real-time data platform. Through this series, you will learn how to collect, store, process, analyze, and expose data in real time using a wide variety of tools provided by Redis.
Redis is an open-source, in-memory datastore used as a database, cache, streaming engine, and message broker. It supports various data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. In addition, Redis provides a sub-millisecond latency with very high throughput: up to 200M Ops/sec at a sub-millisecond scale, which makes it the obvious choice for real-time use cases.
In the last posts, I explained that data architecture is a pivotal component of any data strategy. So, unsurprisingly, choosing the right data architecture should be a top priority for many organizations. Data architectures can be classified based on data velocity, and the most popular ones in this category are Lambda and Kappa.
In this first article, I will illustrate how Redis can implement each of these architectures using the myriad of tools and features it provides. A detailed implementation of each data lifecycle stage will be published in future posts.
What makes a “Good” Data Architecture?
You know “good” when you see the worst. Bad data architectures are tightly coupled, rigid, overly centralized, and use the wrong tools for the job, hampering development and change management. A good data architecture should primarily serve business requirements with a widely reusable set of building blocks while preserving well-defined best practices (principles) and making appropriate trade-offs. We borrow inspiration for “good” data architecture principles from several sources, especially the AWS Well-Architected Framework. It consists of six pillars:
- Performance efficiency: A system’s ability to adapt to load changes.
- Reliability: The ability of a system to recover from failures and continue to function.
- Cost optimization: Managing costs to maximize the value delivered.
- Security: Protecting applications and data from threats.
- Operational excellence: Operations processes that keep a system running in production.
- Sustainability: Minimizing the environmental impacts of running the system workloads.
In the second part of this article, I will evaluate the data architectures implemented with Redis regarding this set of principles.
Because data architecture is an abstract discipline, it helps to reason by categories of architecture. The following section outlines prominent examples of famous data architecture today. Though this set of examples is not exhaustive, the intention is to expose you to some of the most common data architecture patterns and make an overview of the trade-off analysis needed when designing a good architecture for your use case.
Lambda data architecture with Redis
The term “Lambda” is derived from lambda calculus (λ) which describes a function that runs in distributed computing on multiple nodes in parallel. Lambda data architecture was designed to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data and allows access to batch-processing and stream-processing methods in a hybrid way. It was developed in 2011 by Nathan Marz, the creator of Apache Storm, as a solution to the challenges of real-time data processing at scale.
The Lambda architecture is an ideal architecture when you have a variety of data workloads and velocities. It can handle large volumes of data and provide low-latency query results, making it suitable for real-time analytics applications like dashboards and reporting. In addition, this architecture is useful for batch processing (e.g., cleansing, transforming, or data aggregation), for stream processing tasks (e.g., event handling, real-time recommendation, anomaly detection, or fraud prevention), and for building centralized repositories known as ‘data lakes’ to store structured/unstructured information.
The critical feature of Lambda architecture is that it uses two separate processing systems to handle different types of data processing workloads. The first is a batch processing system, which processes data in large batches and stores the results in a centralized data store (e.g., a data warehouse or a data lake). The second system is a stream processing system, which processes data in real-time as it arrives and stores the results in a distributed data store.

In the diagram above, you can see the main components of Lambda Architecture implemented with Redis. It consists of the ingestion layer, the batch layer, the speed layer (or stream layer), and the serving layer.
-
Ingestion Layer: In this layer, raw data are extracted from one or more data sources, replicated, then ingested into a landing storage support, for instance, a Redis database. Depending on data Volume and Velocity, you would choose batch ingestion or stream ingestion (differences are extensively discussed here). Redis offers different tools that allow both kinds of ingestion:
First, Redis Input/Output Tools (RIOT) collects and transfers data in and out of Redis in a batch fashion. It consists of several modules that can ingest data from files (using RIOT-File) or from relational databases (using RIOT-DB) and integrate it into Redis.
Redis Data Integration (RDI) is a product that helps ingest and export data in near real-time. RDI allows mirroring several kinds of databases to Redis using the Capture Data Change (CDC) concept. The CDC constantly monitors the database transaction logs and collects changed data into Redis Enterprise without interfering with the database workload. It also collects and integrates event streams from other data sources like Kafka or MQTT brokers.
Real-time or Stream-generating applications can also send their data stream directly to Redis using Redis Streams. Redis Streams is an event streaming system that offers up to 500 times the throughput of Apache Kafka at a sub-millisecond scale.
-
Batch Layer: The batch processing layer is designed to handle large volumes of historical data and store the results in a centralized data store, such as a Redis Database. In fact, Redis is an in-memory data store, so keeping a high volume of data (aka. Big Data) can be very expensive. However, Redis Enterprise allows the creation of Redis on Flash (RoF) databases that extend the memory capacity with SSD (Solid State Drives) disks, enabling you to store significantly more data with fewer resources, thus reducing overall storage costs.
In addition, the batch layer uses frameworks like Apache Spark for efficient information processing, allowing it to provide a comprehensive view of all available data. Spark-Redis library provides access to all Redis’ data structures from Spark as RDDs. It also supports reading and writing with DataFrames and Spark SQL syntax.
-
Speed Layer: The speed layer is designed to handle high-volume data streams and provide up-to-date information views using event processing engines, such as Redis Gears. This layer processes incoming real-time data (e.g., from Redis Data Integration) and retains the results in a message queue like Redis Streams or another specific Redis data structure required by downstream consumers (e.g., JSON, Time Series, Bloom…). In this layer, RediSearch can be used to index, query, and do full-text search on Redis datasets. In addition, it allows multi-field queries, aggregation, exact phrase matching, numeric filtering, geo-filtering, and vector similarity semantic search on top of text queries.
-
Serving Layer: The serving layer of Lambda architecture is essential for providing users with consistent and seamless access to data, regardless of the underlying processing system. Furthermore, it plays an important role in enabling real-time applications like dashboards and analytics that need rapid access to current information. Here you can use Redis Smart Cache, which uses Redis caching capabilities, to cache slow, repeated query results and avoid expensive calls to slower backend systems (e.g., databases, distributed file systems…), improving their response times.
Like most NoSQL databases in the marketplace, Redis doesn’t allow you to query and inspect the data with the Structured Query Language (SQL). Instead, Redis provides a set of commands and a querying language to retrieve the native data structures (Key/values, Hashes, Sets…) and to make multi-field queries. Meanwhile, your business analysts are used to the industry standard, SQL. Many powerful tools rely on SQL for analytics, dashboard creation, rich reporting, and other business intelligence work, but unfortunately, they don’t support Redis commands natively. This is where Redis SQL comes to allow query federation on top of RediSearch.
Redis SQL comes in two flavors: a Trino connector to access Redis data from JDBC-compatible applications like Tableau and an ODBC driver that provides access to ODBC-compatible applications such as Power BI or even Microsoft Excel. Finally, you can use Redis as a vector database that stores Feature Vectors and allows applications like ChatGPT to fetch them simultaneously with Low Latency.
While Lambda architectures offer many advantages, such as scalability, fault-tolerance, and flexibility to handle a wide range of data processing workloads (batches and streams), it also comes with drawbacks that organizations must consider before deciding whether to use or not. In fact, Lambda architecture is a complex system that uses multiple technology stacks to process and store data. In addition, the underlying logic is duplicated in the Batch and the Speed Layers for every stage. As a result, it can be challenging to set up and maintain, especially for organizations having limited resources. However, using Redis as a unique stack for both layers can help reduce the complexity encountered in Lambda architectures.
Kappa data architecture with Redis
In 2014, when he was still working at LinkedIn, Jay Kreps started a discussion where he pointed out some drawbacks of the Lambda architecture. This discussion further led the big data community to another alternative that used fewer code resources.
The principal idea behind this is that a single technology stack can be used for both real-time and batch data processing. This architecture was called Kappa. Kappa architecture is named after the Greek letter “Kappa” (ϰ), which is used in mathematics to represent a “loop” or “cycle.” The name reflects the architecture’s emphasis on continuous data processing or reprocessing rather than a batch-based approach. At its core, it relies on streaming architecture: incoming data is first stored in an event streaming log, then processed continuously by a stream processing engine, like Kafka, either in real-time or ingested into any other analytics database or business application using various communication paradigms such as real-time, near real-time, batch, micro-batch, and request-response.
Kappa architecture is designed to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data in real time. The Kappa architecture is considered a simpler alternative to the Lambda architecture as it uses a single technology stack to handle both real-time and historical workloads, treating everything as streams. The primary motivation for inventing the Kappa architecture was to avoid maintaining two separate code bases (pipelines) for the batch and speed layers. This allows it to provide a more streamlined and simplified data processing pipeline while providing fast and reliable access to query results.

The most important requirement for Kappa was Data reprocessing, making visible the effects of data changes on the results. Consequently, the Kappa architecture with Redis is composed of only two layers: the stream layer and the serving one. The Serving Layer of Kappa is quite similar to Lambda’s one.
The stream processing layer collects, processes, and stores live-streaming data. This approach eliminates the need for batch-processing systems by using an advanced stream processing engine such as Redis Gears, Apache Flink, or Apache Spark Streaming to handle high volumes of data streams and provide fast, reliable access to query results. The stream processing layer is divided into two components: the ingestion component, which collects data from various sources, and the processing component, which processes this incoming data in real-time.
- Ingestion component: This layer collects incoming data from various sources, such as logs, database transactions, sensors, and APIs. The data is ingested in real-time using Apache Kafka or Redis Streams and stored in Redis for processing.
- Processing component: The Processing component of the Kappa architecture is responsible for handling high-volume data streams and providing fast and reliable access to query results. It uses event processing engines like Redis Gears to process incoming data in real-time. In addition, multiple Redis integrations exist for other event processing engines like Apache Flink (Flink Redis Sink), Apache Spark Streaming (Spark-Redis), or Apache Kafka (Redis Kafka connectors).
Nowadays, real-time data beats slow data. That’s true for almost every use case. Nevertheless, Kappa Architecture cannot be taken as a substitute for Lambda architecture. On the contrary, it should be seen as an alternative to be used in those circumstances where the active performance of the batch layer is not necessary for meeting the standard quality of service.
One of the most famous examples that leverage Kappa Architecture with Redis is the IoT architecture. The Internet of Things (IoT) is a network of physical devices, vehicles, appliances, and other objects (aka, things) embedded with sensors, software, and connectivity that enables them to collect and exchange data. These devices can be anything from smart home appliances to industrial machinery to medical devices, and they are all connected to the Internet. As you can imagine, this kind of architecture might generate millions of operations per second and needs to process them in very low latency. This makes Redis the perfect choice for such a scenario.
The data collected by IoT devices can be used for various purposes, such as monitoring and controlling devices remotely, optimizing processes, improving efficiency and productivity, and enabling new services and business models. IoT Data is generated from devices that collect data periodically or continuously from the surrounding environment and transmit it to a destination.

An event producer is a device in this architecture, which isn’t beneficial unless you can get its data. So, an IoT gateway is a critical component that collects and securely routes device data to the appropriate destinations on the internet. IoT gateways work as event brokers and use standards and protocols like MQTT1 and OPC UA2 to communicate over the Internet. From there, events and measurements can flow into an event ingestion architecture with all challenges it brings—e.g., late-arriving data, data structure and schema disparities, data corruption, and connection disruption.
The storage and processing requirements for an IoT system will vary greatly depending on the latency requirements of the IoT devices. For instance, if remote sensors are collecting scientific data that will be analyzed at a later time, batch storage and processing may be sufficient. Conversely, if a system backend constantly analyzes data in a home monitoring, or an automation solution, near real-time responses may be necessary.
A Kappa Architecture with Redis would be more suitable in such a case. With Redis Streams and the different Redis modules (time-series, RediSearch…), you can address these requirements since it is designed to support high throughput and sub-millisecond latency at scale. In addition, Redis Data Integration has specific connectors for both MQTT and OPC UA. These connectors allow getting events from IoT gateways (e.g., MQTT Brokers) into Redis through Redis Streams.
Like the previous architectures, Redis Smart Cache and Redis SQL work as accelerators to provide users with consistent and seamless access to IoT data. They play essential roles in enabling real-time applications like dashboards and analytics that need rapid access to current information.
In Industry 4.0, machine-to-machine communications enable automation and data-driven monitoring that can, for example, identify defects and vulnerabilities on their own. Large volumes of data must be processed in near real-time for all these scenarios and made available worldwide across plants and companies. Using Redis Enterprise, you can leverage an Active-Active architecture to distribute your IoT architecture over multiple data centers via independent and geographically distributed clusters and nodes. Active-Active Geo-Distributed topology is achieved by implementing CRDTs (conflict-free replicated data types) in Redis Enterprise using a global database that spans multiple clusters while maintaining low latency within each region.
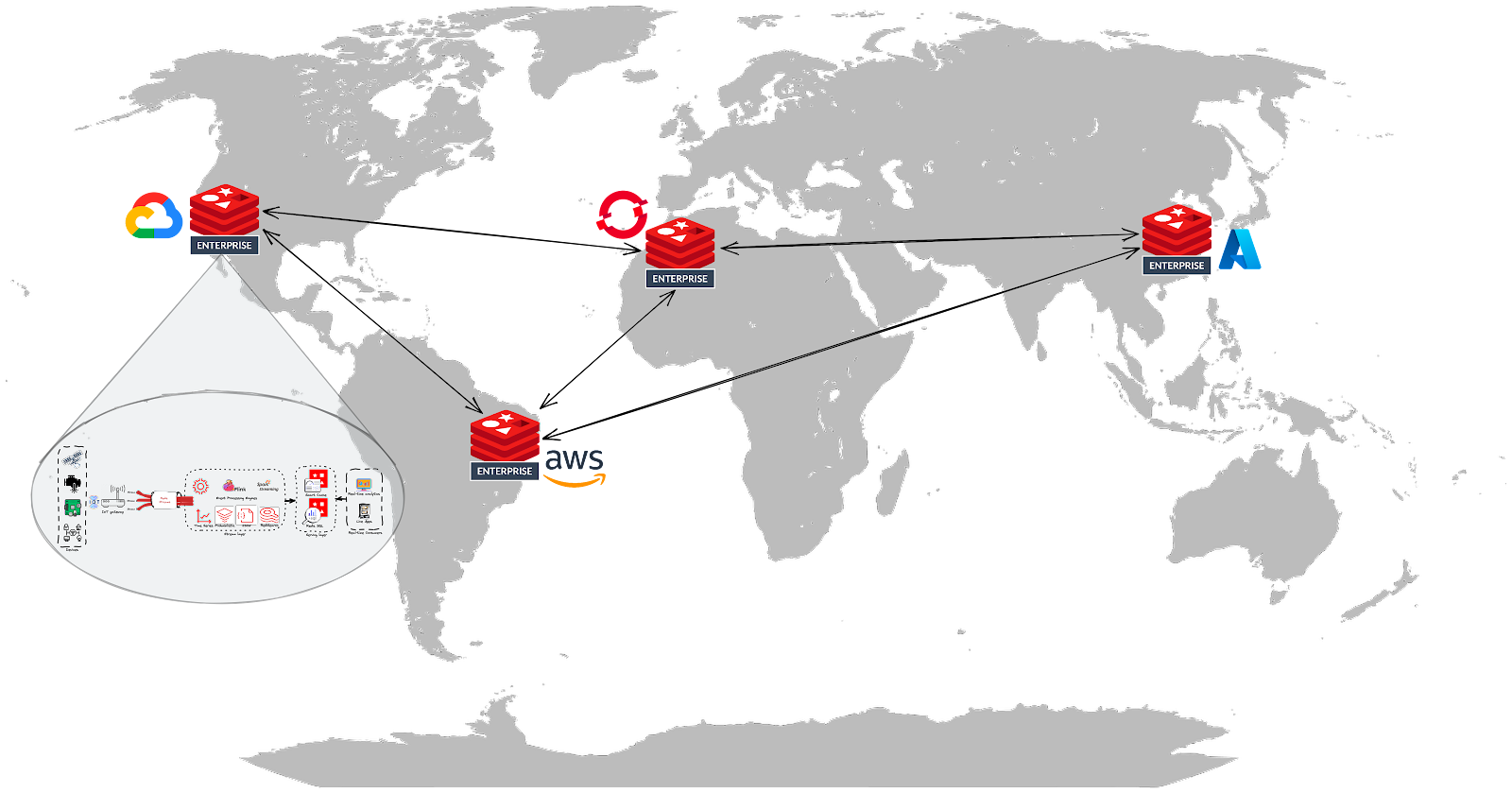
The essential requirement here is integrating various systems, such as edge and IoT devices, independently of the underlying infrastructure (edge, on-premises, containerized, as well as the public, multi-, and hybrid cloud). For this, Redis supports several deployment options:
- RedisEdge: a purpose-built, multi-model database for the demanding conditions at the Internet of Things (IoT) edge. It can ingest millions of writes per second with sub-millisecond latency and a tiny footprint (less than 5MB), so it easily resides in constrained compute environments. In addition, it can run on various edge devices and sensors ranging from ARM32 to x64-based hardware;
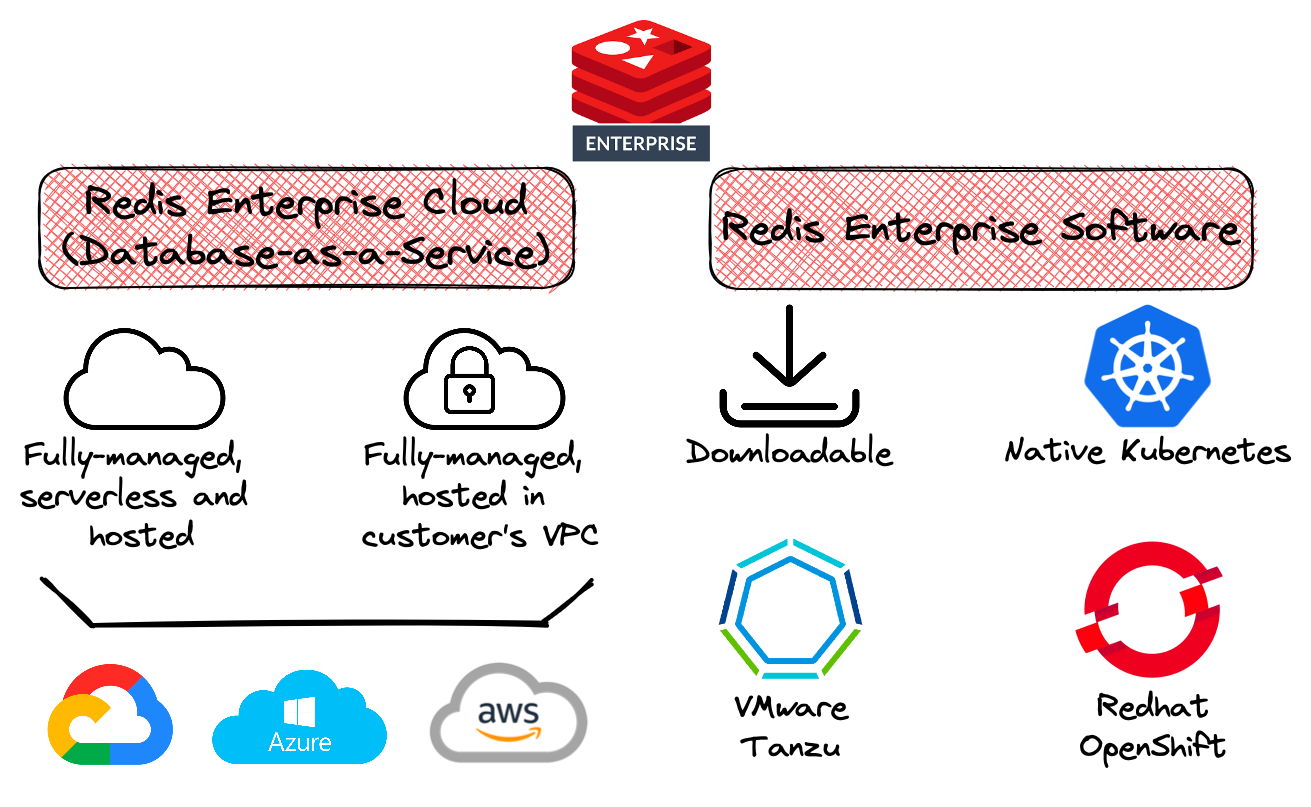
- Redis Enterprise Software (RS): the on-premises distribution of Redis Enterprise that can be deployed in:
- IaaS cloud environments - Amazon Web Services (AWS), Google Cloud, and Microsoft Azure;
- Bare-metal servers in a private data center;
- Virtual machines (VMs), Kubernetes pods, etc.
- Redis Enterprise Cloud (RC): the fully-managed cloud service is based on Redis Enterprise and provided as a Database-as-a-Service (DBaaS).
Although the concept of IoT devices dates back several decades, the widespread adoption of smartphones created a massive swarm of IoT devices almost overnight. Since then, various new categories of IoT devices have emerged, including smart thermostats, car entertainment systems, smart TVs, and smart speakers. The IoT can revolutionize many industries, including healthcare, manufacturing, transportation, and energy. It has transitioned from a futuristic concept to a significant domain in data engineering. It is expected to become one of the primary ways data is generated and consumed.
Data Architectures with Redis: are they “Good” Architectures?
As discussed earlier, The AWS Well-Architected framework is designed to help cloud architects create secure, reliable, high-performing, cost-effective, and sustainable architectures. This system consists of six key pillars: operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability, providing customers with a consistent way to evaluate and implement scalable architectures. I borrowed inspiration for “good” data architecture principles from the AWS Well-Architected Framework and assessed whether Redis can make “good” data architectures or not.
1. Performance efficiency stands for the ability of a system to adapt to load changes. The Main challenge we can observe with many data architectures is the operational complexity when deploying and managing their technical tools and solutions. More often, it is difficult to anticipate and handle demand peaks of such platforms resulting in wasted money on underused resources, already over-provisioned due to poor scaling process. With Redis, the primary storage unit is the shard, and it can be scaled up and out to form a cluster, thus fitting the demand peaks in your platform. Moreover, all components of Redis Enterprise provide linear scalability, making it a good choice for high throughput workloads at sub-millisecond latency.

2. Reliability: “Reliability is the precondition for trust.”3 This mantra is valid in data architecture, especially when end-users seek real-time decision-making. Reliability stands for The ability of a system to recover from failures and continue to function as expected. The main challenge when it comes to a data platform’s reliability is the difficulty to meet required SLAs. Downtimes or slow response times can consequently lead to revenue loss, damaged reputation, and customer churn. With Redis Enterprise, your data architecture will benefit from the replicated architecture (intra-node, inter-nodes, anti-affinity…) and the failover mechanisms implemented in Redis Enterprise, in addition to advanced capabilities like the active-passive and the active-active replications, which provide up to 99.999% of uptime SLA (around 5min of downtime per year).
3. Cost optimization stands for managing costs to maximize the value delivered. Redis Enterprise implements a “share-nothing” architecture that allows various Redis instances to run inside a node without any awareness of each other and therefore isolated to prevent them from affecting one another. As a result, Redis Enterprise provides Noisy-neighbor cancellation, Minimizing CPU consumption of inactive applications. In addition, another advantage of this multi-tenancy is the ability to share infrastructure capabilities by multiple databases, thus reducing the Total Cost of Ownership (TCO) of your data platform (30% to 70% of cost reduction).
Another lever that optimizes your data architecture cost is data tiering. As you know, Redis is an in-memory data store, and using memory (RAM) to store significant volumes of data is very expensive. However, Redis Enterprise allows you to optimize your costs by performing data tiering: keeping only the hot data (frequently accessed) and the keys in memory and putting the Cold/Warm Data (accessed less frequently) in a flash disk (e.g., Solid State Disk or NVMe storage). This can reduce the cost by up to 80% while preserving high throughput and low latency.
 Redis Data Tiering.
Redis Data Tiering.
4. Security stands for protecting the data platform from threats. Although security is often perceived as a hindrance to the work of data engineers, they must recognize that security is, in fact, a vital enabler. By implementing robust security measures (encryption, mutual TLS, trusted CA…) for data at rest and in motion and fine-grained data access control, a data architecture using Redis can enable wider data sharing and consumption within a company, leading to a significant increase in data value. In addition, the principle of least privilege is implemented through Access Control List (ACL) and Role-Based Access Control (RBAC), meaning that data access is only granted proportionally to those who require it.
5. Operational excellence is the ability to keep a system running in production optimally. First, Redis Enterprise provides multiple integrations to allow operational monitoring of your data platform, the underlying infrastructure, and data access (audit trail). Thus, you can gain visibility and take the appropriate actions.
6. Sustainability tends to minimize your data platform’s environmental footprint. Redis Enterprise supports several deployment options that allow you to choose the storage technologies and configurations that best support the business value of your data (multi-cloud, hybrid cloud). In addition, features like multi-tenancy and data tiering can reduce the provisioned infrastructure required to support your data platform and the resources needed to use it. Consequently, using Redis helps reduce the environmental footprint of your data platform.
Summary
In this article, I introduce Redis as a real-time data platform that provides an implementation for the most popular data architectures using the myriad of tools and features it provides. But first, I explained how fast data beats slow one and how Redis, as an in-memory data store, is well-suited for this purpose.
Then, the article skims a few use cases for Redis, such as implementing a real-time recommendation engine, handling real-time analytics, building a conversational application (like chatGPT), and addressing Industry 4.0 requirements with an IoT architecture. In the following articles, I’ll delve into detailed explanations of how Redis can be used in each of these scenarios and for each stage of the data journey.
Overall, this article provides a comprehensive overview of how Redis can be used as a real-time data platform and the various data architectures that can be implemented using Redis. Then I evaluated these architectures, regarding the AWS Well-Architected Framework, to assess if those are “good” data architectures. The result of this evaluation provides valuable insights into building well-architected data platforms.
References
- Akidau T. et al., The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Proceedings of the VLDB Endowment, vol. 8 (2015), pp. 1792-1803.
- Reis, J. and Housley M. Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media (2022).
- “Lambda vs. Kappa Architecture. A Guide to Choosing the Right Data Processing Architecture for Your Needs”, Dorota Owczarek.
- “A brief introduction to two data processing architectures — Lambda and Kappa for Big Data”, Iman Samizadeh, Ph.D.
- “What Is Lambda Architecture?”, Hazelcast Glosary.
- “What Is the Kappa Architecture?”, Hazelcast Glosary.
- “Kappa Architecture is Mainstream Replacing Lambda”, Kai Waehner.
- “Data processing architectures – Lambda and Kappa”, Julien Forgeat.
1. Message Queuing Telemetry Transport (MQTT) is an OASIS standard messaging protocol for the Internet of Things (IoT) built on top of TCP/IP for constrained devices and unreliable networks. It is designed as an extremely lightweight publish/subscribe messaging transport, ideal for connecting remote devices with a small code footprint and minimal network bandwidth. MQTT today is the standard of IoT messaging, especially for Industry 4.0.
2. OPC Unified Architecture (OPC UA) is also a machine-to-machine communication protocol used for industrial automation and developed by the OPC Foundation.
3. Wolfgang Schäuble - a German lawyer, politician, and statesman whose political career spans over five decades.