The Data journey or the data value chain describes the different steps in which data goes from its creation to its eventual disposal. The data journey consists of many stages. The main ones are ingestion, storage, processing, and serving. Each stage has its own set of activities and considerations.
Data Storage refers to how data is retained once it has been acquired. While storage is a distinct stage in the data journey, it intersects with other phases like ingestion, transformation, and serving. Storage runs across the entire data journey, often occurring in multiple places in a data pipeline, with storage systems crossing over with source systems, ingestion, transformation, and serving. In many ways, how data is stored impacts how it is used in all the stages of the data journey.
To understand storage, we will start by studying the different levels of storage abstractions and characteristics, such as storage lifecycle (how data will evolve), storage options (how data can be stored efficiently), storage layers, storage formats (how data should be stored depending on data access frequency), and the storage technologies in which data are kept.
Storage levels of abstraction
“Storage” means different things to different users. When we talk about storage, some people think about how data is stored physically; some focus on the raw material that holds the storage systems, while others think about the relevant storage system or technology for their use case. All these levels are important attributes of Storage, but they focus on different levels of abstraction.
 Storage abstractions.
Storage abstractions.
Despite some storage abstraction levels being out of data engineers’ control, It’s essential to understand their basic characteristics to assess the trade-offs inherent in any storage architecture. The following sections discuss the different storage abstraction levels.
How Data is Stored?
Most references use the number of bytes as a measure of storage capacity. Data to be processed is coded in a binary (base-2 number) form using various encoding schemes discussed below:
- To begin with, digits 0 and 1 are binary digits, and each is referred to as a bit for short: 0 represents an OFF state, and 1 represents an ON state.
- Given n bits contained in a storage support, there are 2n (read “2 to the power or n”) ways in which zeros and ones can be arranged, e.g., given 2 binary digits (either 1 or 0), arrangements may be one of four (22 or 2x2 or 4) possibilities - 00, 01, 10 and 11.
- The industry settled on a sequence of 8-bits (given the unit name byte) as the basic storage unit.
- The term byte preceded by a prefix expresses the storage capacity.
Units for Measuring Data Storage Capacity:
| 1 Bit | = 1 Binary Digit |
| 4 Bits | = 1 Nibble |
| 8 Bits | = 1 Byte |
| 210= 1024 Bytes | = 1 Kilobyte |
| 220= 1024 Kilobyte | = 1 Megabyte |
| 230= 1024 Megabyte | = 1 Gigabyte |
| 240= 1024 Gigabyte | = 1 Terabyte |
| 250= 1024 Terabyte | = 1 Petabyte |
Raw Storage Support
Storage is ubiquitous, which makes it easy to overlook its significance. For example, many software and data engineers use storage daily, yet they may need to gain more knowledge of how it operates and the trade-offs involved with different storage media.

Data in data journeys typically goes through various storage media such as magnetic storage, SSDs, and memory during different stages of the data pipeline. Storage and query systems are complex and require distributed systems, multiple hardware storage layers, and numerous services to function effectively. These systems require the right components to operate correctly. Therefore, it is crucial to understand these underlying systems and the ingredients required to ensure efficient and effective data processing. These are the different components that operate harmoniously to provide a storage media:
- CPU: Why do we mention CPU as raw data storage support? The CPU (Central Processing Unit) is responsible for managing data movement and access from the storage media (HDD, SDD..) into memory and executing operations on it. The CPU uses input/output (I/O) operations to read and write data from storage, and it performs data operations on the data loaded into memory. So next time you think about the storage throughput (the number of operations per second you can perform on storage), you are dealing with the CPU.
- Networking considerations play a crucial role in the design and implementation of data architectures, and it is important for data engineers to clearly understand their impact. They must navigate the trade-offs between the geographic distribution of data for improved durability and availability versus keeping data storage in close proximity to its users or producers for better performance and cost-effectiveness.
- Serialization: Typically, data stored in system memory by software is not in a format suitable for disk storage or network transmission. To address this, data is serialized, which involves flattening and packing it into a standardized format that can be decoded by a reader. Serialization formats provide a common data exchange standard, but each choice comes with its own trade-offs. Therefore, data engineers must carefully select the serialization format and tune it to optimize performance for specific requirements.
- Compression is a crucial aspect of storage engineering as it can significantly reduce data size. However, compression algorithms can also interact with other storage system details in complex ways. Highly efficient compression offers three main advantages in storage systems. First, compressed data takes up less space on the disk. Second, compression improves the practical scan speed per disk. For instance, with a 10:1 compression ratio, the effective rate increases from scanning 200 MB/s per magnetic disk to 2 GB/s per disk. The third advantage is in network performance. A 10:1 compression ratio can increase effective network bandwidth from 10 gigabits per second (Gbps) to 100 Gbps, especially when transferring data between systems. Compression also comes with disadvantages. Compressing and decompressing data entail extra CPU consumption to read or write data.
On top of these components, one or many storage media can be implemented to provide the storage capacity; this is a short list of the most used ones:
- Magnetic Disk Drive (HDD): a type of storage device that uses rotating disks coated with a ferromagnetic material to store data. The disks rotate at high speeds while read/write heads move back and forth over the disk surface to read and write data. When data is written to a magnetic disk drive, an electrical current is used to magnetize tiny spots on the disk surface. These spots represent the data being stored. When data is read from the disk, the read/write heads use electrical signals to detect the magnetic fields on the disk surface and translate them into digital data that can be read by the computer.

Despite advancements in the capacity of hard disk drives (HDDs), their performance is limited by physical constraints. One such limitation is the disk transfer speed, which refers to the rate at which data can be read and written. The transfer speed does not increase proportionally with disk capacity as it scales with linear density (bits per inch), whereas disk capacity scales with areal density (gigabits stored per square inch). As a result, if the disk capacity grows by a factor of 4, the transfer speed only increases by a factor of 2. A second major limitation is seek time. To access data, the drive must physically relocate the read/write heads to the appropriate track on the disk. Third, in order to find a particular piece of data on the disk, the disk controller must wait for that data to rotate under the read/write heads. This leads to rotational latency.
- Solid-State Drive (SSD) uses flash memory cells to store data as charges, thus eliminating the mechanical constraints of magnetic drives. Therefore, the data is read by purely electronic means. As a result, SSDs are much faster than traditional magnetic drives, and they can retrieve random data in less than 0.1 ms (100 microseconds). They can also scale data transfer speeds and IOPS by dividing storage into partitions with multiple storage controllers running in parallel. Thanks to these exceptional performance characteristics, they have revolutionized transactional databases and are the accepted standard for commercial deployments of OLTP systems. With SSDs, relational databases such as PostgreSQL, MySQL, and SQL Server can handle thousands of transactions per second. However, SSDs come with a cost. Commercial SSDs typically cost 20–30 cents (USD) per gigabyte of capacity, nearly 10 times the cost per capacity of a magnetic drive.
- Magnetic Tape Drive: Similar to HDDs, Tape drives are storage devices that use magnetic tape to store and retrieve data. They were widely used for backup and archival storage but have become less familiar with the rise of disk-based storage. Tape drives work by passing a magnetic tape over a read/write head that magnetizes or reads the data on the tape. The tape is wound on two spools, with one spool holding the tape that has not been used and the other spool holding the tape that has already been used. The tape is pulled from the unused spool and wound onto the used spool as the read/write head moves back and forth across the tape.
Tape drives have several advantages over other types of storage devices. They have a low cost per gigabyte of storage, can hold large amounts of data, and are very reliable for long-term storage (this is why they are used for archiving cold data). - Random Access Memory (RAM): commonly called memory, it is used to temporarily store data that is currently being used or processed by the computer’s CPU. RAM provides the CPU with fast access to this data, allowing it to read and write data quickly. RAM is considered volatile memory, meaning that it loses its data when the computer is turned off. It differs from long-term storage devices like hard drives and solid-state drives, which retain data even when the computer is turned off. The amount of RAM a computer has can significantly affect its performance, as more RAM allows more data to be stored and accessed quickly. Memory is partitioned (divided) into several data containers called memory cells. Each cell stores a specific amount of data called a word. Each cell has an associated location identifier called an address. The capacity of memory is determined by the number of bits per cell and the number of cells into which memory has been partitioned, i.e., it depends on how many bits may be stored in each cell and how many cells there are available.
Storage systems
Storage systems exist at a level of abstraction above raw storage supports. For example, magnetic disks are raw storage supports, while major cloud object storage platforms and HDFS are storage systems that utilize magnetic disks.
Storage systems define how the storage layer holds, organizes, and presents data independently on the underlying storage support. Data can be stored in different formats:
- File storage: also known as file-level or file-based storage, is a method of storing data where each piece of information is kept inside a folder (hierarchical storage). To access the data, your computer needs to know the path it’s located at. This kind of storage (referred to as “File Systems”) uses limited metadata that tells the computer exactly where to find the files, similar to how you would use a library card catalog for books. The most familiar type of file storage is the operating system–managed filesystems on local disk partitions (e.g., NTFS, etx4). Local filesystems generally support full read-after-write consistency; reading immediately after a write will return the written data. Operating systems also employ various locking strategies to manage concurrent writing attempts to a file. Another well-known file storage is the NAS. Network-Attached Storage or NAS systems provide a file storage system to clients over a network. NAS is a prevalent solution for servers; they quite often ship with built-in dedicated NAS interface hardware.
- Block storage divides data into blocks and stores them individually, each with a unique identifier. This allows the system to store these smaller pieces of information in the most efficient location. Block storage is an excellent solution for businesses that require quick and reliable access to large amounts of data. It allows users to partition their data so it can be accessed in different operating systems, allowing them to configure their own data. Additionally, block storage decouples the user’s data from its original environment by spreading it across multiple environments, which are better suited for serving this information when requested. This makes retrieving stored blocks faster than file-based solutions, as each block lives independently without relying on one single path back to the user’s system. Block storage is usually deployed in Storage Area Network (SAN) environments and must be connected to an active server before use.
- Object storage is a flat structure in which files are broken into pieces and spread out among hardware. Instead of being kept as files in folders or blocks on servers, the data is divided into discrete units called objects with unique identifiers for retrieval over a distributed system. These objects also contain metadata describing details, such as age, privacies/securities, access contingencies, and other information related to the data’s content. Object storage is best used for large amounts of unstructured data, especially when durability, unlimited storage, scalability, and complex metadata management are relevant factors for overall performance. The storage operating system uses the metadata and identifiers to retrieve the data, which distributes the load better and lets administrators apply policies that perform more robust searches. In addition, object storage offers cost efficiency since users only pay for what they use; it can easily scale up to large quantities of static data, and its agility makes it well-suited for public cloud storage applications.

Storage technologies
Choosing a storage technology depends on several factors, such as use cases, data volumes, ingestion frequency, and data format. There is no universal storage recommendation that fits all scenarios. Every storage technology has its pros and cons. With countless varieties of storage technologies available, it can be overwhelming to select the most suitable option for your data architecture.
Over the past years, we’ve seen many storage support technologies that emerged to store and manage data: databases, data warehouses, data marts, data lakes, or, recently, data lakehouses. All start with “data.” Of course, data are everywhere, but the kind of data, scope, and use will illustrate the best technology for your organization.
A database is a structured data collection stored on a disk, memory, or both. Databases come in a variety of flavors:
-
Structured databases: a database that stores data in an organized, pre-defined format (schemas). Structured databases typically store large amounts of information and allow for quick retrieval by using queries. Structured databases can be relational or analytical:
- relational databases that use the relational model to organize data into tables, fields (columns), and records (rows). These tables can be linked using relationships between different fields within each table. This type of database allows complex queries (joins) on large datasets and transactions such as updates, inserts, or deletes across multiple related records at once (OLTP). OLTP systems typically use normalized tables with a few columns containing only the most essential data needed for transactional operations.
- analytical databases are designed for complex analytical tasks like trend analysis and forecasting. These databases (OLAP) usually have large amounts of denormalized data stored in fewer but wider tables, with many columns containing detailed information about each transaction or event being analyzed.
-
Semi-structured & Unstructured databases, also known as Not-Only SQL (NoSQL), do not follow the same structure as traditional SQL databases but instead allow users to store unstructured or semi-structured data without having to define fixed schemas beforehand like you would need when working with a relational database. They also provide more flexibility than their counterparts by allowing developers to quickly add new features without needing extensive modifications or migrations from existing structures due to their dynamic nature. These databases hold data in different manners and can be classified into eight categories:
- Document Databases: These databases store data in documents organized into collections containing key-value pairs or other complex nested structures (e.g., JSON).
- Key-Value Stores: This type of NoSQL database stores each item as an attribute name (or “key”) together with its value; they provide a simple way to store large amounts of structured data that can be quickly accessed by specifying the unique key for each piece of information stored within them. Most key-value stores are in-memory databases that store all their data in the main memory (RAM) instead of on disk. This allows for faster access to the stored keys and provides better performance when dealing with large amounts of data.
- Columnar Databases: this type is optimized for queries over large datasets—storing columns of data separately rather than rows—and typically offers faster write performance compared to row-oriented systems like relational databases due to their ability to add new columns on the fly without having to rewrite existing records or tables entirely when schema changes occur during development cycles.
- Graph Database: A graph database uses nodes connected by edges, making it ideal for applications where relationships between entities need quick access times & efficient storage capacity.
- Time-series databases: A time-series database is a NoSQL database optimized for storing and analyzing time-series data. Time series data is a sequence of data points, typically consisting of timestamps and values, that are collected over time. Time series databases store and analyze data such as sensor readings, stock prices, system metrics, application performance monitoring (APM), log events, website clickstreams, etc.
- Immutable Ledgers: An immutable ledger is a record-keeping system in which records (or “blocks”) cannot be altered or deleted once written. This feature makes them well-suited for applications such as financial transactions, supply chain management, and other scenarios where it’s essential to maintain a permanent auditable trail of all transactions. One of the most well-known examples of an immutable ledger is the blockchain, the underlying technology for cryptocurrencies like Bitcoin. In a blockchain, each block in the chain contains a record of multiple transactions, and once a block is added to the chain, it cannot be altered or deleted. This provides a secure, decentralized ledger of all transactions resistant to tampering and manipulation.
- Geospatial databases: A geospatial datastore is a type of database that specifically stores and manages geospatial data, which describes the location and spatial relationships of objects and features on the Earth’s surface. Geospatial data stores are used to support various applications, such as geographic information systems (GIS), mapping, and spatial analysis. They allow users to perform complex spatial analysis, create maps, and make location-based decisions based on the data they contain.
- Search databases: Search databases are explicitly designed for searching and retrieving information based on specific criteria, such as keywords or vectors. They are commonly used in applications that require fast and efficient searching, such as e-commerce websites, online libraries, and digital archives. Search databases use various indexing and data structure techniques to optimize search performance, such as inverted indexes, B-trees, and hash tables. In addition, they often provide advanced features such as fuzzy search, synonym matching, relevance ranking, and vector similarities.

A data warehouse is a standard OLAP data architecture (don’t dare to call it an analytical database, Bill Inmon will be upset). It tends to handle large amounts of data quickly, allowing users to analyze facts according to multiple dimensions in tandem (Cube). Data warehouses have been a staple in decision support and business intelligence applications since the late 1980s. However, they are not well-suited to handle large volumes of unstructured or semi-structured data with a wide variety, velocity, and volume; thus making them an inefficient choice as a big data storage technology. Furthermore, data warehouses can contain a wide variety of data from different sources. For various usages (i.e., Enterprise Data Warehouse), it can be used for near real-time analysis and reporting on operational systems that are constantly changing or updating their data sets (ODS), or they can be split into many subsets and tailored for specific usages or operational purposes (i.e., data marts).
About a decade ago, architects began to conceptualize a single system for storing data from multiple sources that could be used by various analytic products and workloads. This led to the development of data lakes. A data lake is a large, centralized repository of structured and unstructured data that can be used for any scale.
Unlike databases or data warehouses, a data lake captures anything the organization deems valuable for future use. The data lake represents an all-in-one process. Data comes from disparate sources and serves disparate consumers. We often see data lakes working with complimentary tools like data warehouses, which provide more querying options and other analytical features, and data marts because they create the other side of the spectrum: While data lakes are enormous repositories of raw data, data marts are more focused on specialized data (subject-oriented data).
 Demystifying Data Storage - Credit Marc Lamberti.
Demystifying Data Storage - Credit Marc Lamberti.
The continuous need for complimentary tools pushed many technology vendors to create a new concept that combines the best elements of data lakes and data warehouses. This new technology is called data lakehouses.
A data lakehouse combines the low-cost, scalable storage of a data lake and the structure and management features of a data warehouse. This environment allows for cost savings while still enforcing schemas on subsets of the stored data, thus avoiding becoming an unmanageable “data swamp.” For this, It comes with the following features (non-exhaustive list):
- Data mutation: Most data lakes are built on top of immutable technologies (e.g., HDFS or S3). This means that any errors in the data cannot be corrected. To address this schema evolution problem, data lakehouses allow two turnarounds: copy-on-write and merge-on-read.
- ACID: support transactions to enable concurrent read and write operations while ensuring data is ACID (Atomic, Consistent, Isolated, and Durable).
- Time-travel: The transaction capability of the lakehouse allows for going back in time on a data record by keeping track of versions.
- Schema enforcement: Data quality has many components, but the most important is ensuring that data adheres to a schema when ingested. Any columns not present in the target table’s schema must be excluded, and all column types must match up correctly.
- End-to-end Streaming: organizations face many challenges with streaming data. One example is the out-of-order data, which the data lakehouse solves through watermarking. It supports also merge, update, and delete operations to enable complex use cases like change-data-capture (CDC), slowly-changing-dimension (SCD) operations, streaming upserts, etc.

Storage Features
1 - Storage layers
The data lake architecture was initially thought to be the solution for storing massive volumes of data. Still, they have instead become data swamps filled with petabytes of structured and unstructured information that cannot be used.
To combat this issue, it is important to understand how to create zones within a data lake in order to effectively drain the swamp.
Data lakes are divided into three main zones: Raw, Trusted, and Curated. Organizations may label these zones differently according to individual or industry preference, but their functions are identical.
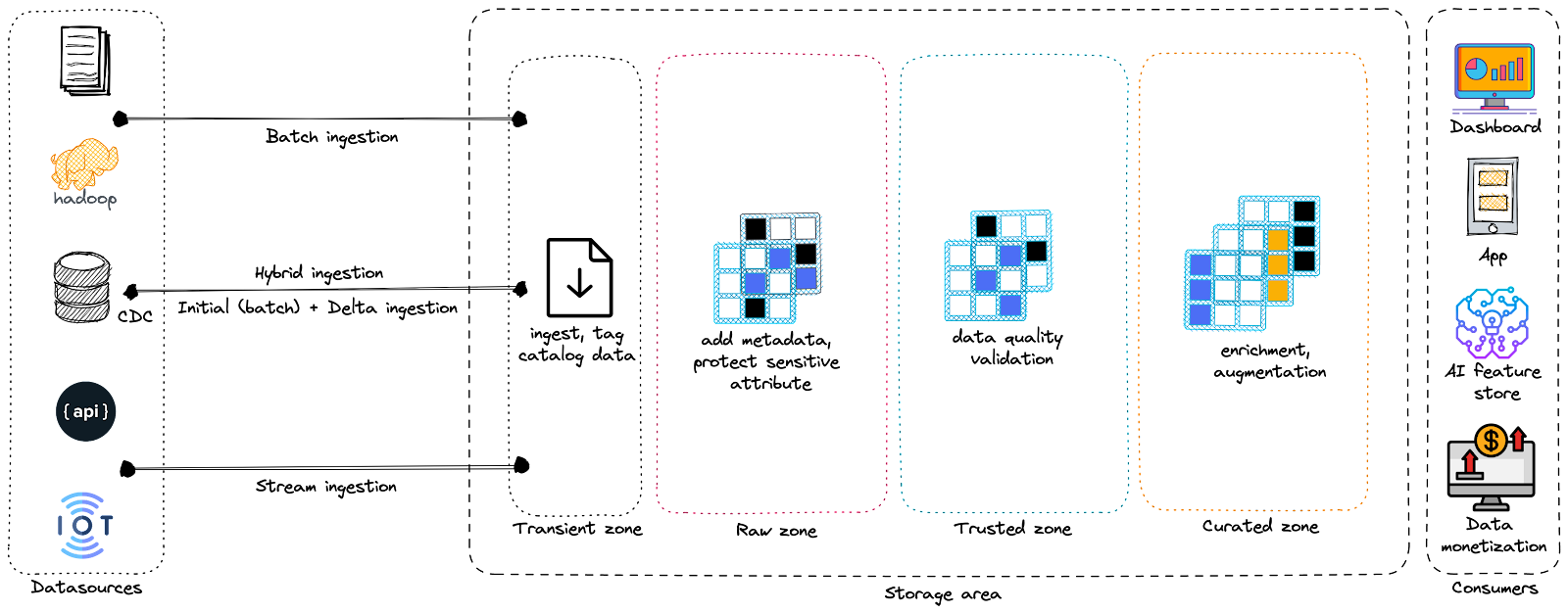
- Raw zone: also known as the landing zone, the bronze zone, or the swamp. In this zone, data is stored in its native format without transformation or binding to any business rules. Though all data starts in the raw zone, it’s too vast of a landscape for business end-users (less technical). Typical users of the raw zone include data engineers, data stewards, data analysts, and data scientists, who are defined by their ability to derive new knowledge and insights amid vast amounts of data. These users spend a lot of time sifting through data, then pushing it into other zones.
- Trusted zone: also called the exploration zone, the sandbox, the silver zone, or the pond. This is the place where data can be discovered and explored. It includes private zones for each individual user and a shared zone for team collaboration. The trusted data zone holds data as a universal “source of truth” for downstream zones and systems. A broader group of users has applied extensive governance to this data, with more comprehensive definitions that the entire organization can stand behind.
- Curated zone: also known as the refined data, the production zone, the gold zone, the service zone, or the lagoon. This is where clean, manipulated, and augmented data are stored in the optimal format to drive business decisions. In addition, it offers operational data stores that feed data warehouses and data marts. This zone has strict security measures to limit data access and provides automated delivery of read-only data for end users.
In some platforms, you can find additional transient or transit zones that hold ephemeral unprocessed data (i.e., temporary copies, streaming pools…) stored temporarily before being moved to one of the three permanent zones.
2 - Storage lifecycle
Data retrieval patterns can vary significantly based on the nature of the stored data and the queries made. As a result, the concept of “temperatures” has emerged. The frequency of data access determines the temperature of the data.
Data that is accessed most frequently is known as hot data. Hot data may be accessed multiple times daily or even several times per second, such as in systems that process user requests. This data must be stored in a manner that allows quick retrieval, with “fast” defined in the context of the use case. Warm data is accessed occasionally, such as once a week or month.
Cold data is rarely queried and is best stored in an archival system. However, cold data is often retained for compliance reasons or as a safeguard in the event of a catastrophic failure in another system. In the past, cold data was stored on tapes and sent to remote archival facilities. In cloud environments, vendors provide specialized storage tiers with meager monthly storage costs but high retrieval fees.
It is necessary to put in place some policies to handle data storage depending on data “temperature” or the degree of its reliability. This is why the storage lifecycle becomes a critical task.

The storage lifecycle is the process of managing stored data throughout its entire lifecycle, from the initial creation in the support to eventual deletion. In your data platform, you should manage your data objects with a set of rules that define actions to apply when predefined conditions are verified. There are two types of actions:
-
Transition actions define when data objects transition from one isolated zone to another. In most data platforms, the landing zone is the first storage area in which raw data is ingested. It is then necessary to set transition actions to transfer data from one storage area to another (e.g., curated, augmented, or conformed…).
You can also define when data objects transition from one storage class to another (e.g., label data as cold when it is less frequently used or archive data older than one year), which can give better control over storage costs.
-
Expiration actions: you can define when your data should be removed (expired).
These kinds of actions are usually performed by ETL tools, but some storage services (especially those provided by Cloud Vendors) can offer such capabilities (e.g., AWS S3 lifecycle policies).
3 - Storage options
Storing data collected from multiple sources to a target storage system has always been a global challenge for organizations. Therefore, the chosen storage option is an area of interest for improving the data journey. You either employ the bulk method (also called full load) or the incremental Load method for performing data storage.
In bulk storage, the entire target dataset is cleared out and then entirely overwritten: replaced with an updated version during each data loading run. Performing a full data load is an easy-to-implement process requiring minimal maintenance and a simple design. This technique simply deletes the old dataset and replaces it with an entire updated dataset, eliminating the need to manage deltas (changes). Furthermore, if any errors occur during these loading processes, they can be easily rectified by rerunning them without having to do additional data cleanup/preparation.
However, using the full data load approach, one may experience difficulty in sustaining data loading with a small number of records (when you need to update only a few values but you have to erase then insert millions of objects), slow performance when dealing with large datasets and an inability to preserve historical data.
 Bulk vs. Incremental storage.
Bulk vs. Incremental storage.
On the other hand, the incremental load is a selective method of storing data from one or many sources to a target storage location. The incremental load model will attempt to compare the incoming data from the source systems with the existing data present in the destination for any new or changed data values since the last loading operation. Of course, some storage systems keep track of every modification, as a versioning control system could do.
The key advantage of incremental storage over a full bulk load is that it minimizes the amount of work needed with each batch. This can make incremental loading much faster overall, especially when dealing with large datasets. In addition, since only new or changed data is stored each time, there is less risk of errors introduced into the target datasets. Finally, keeping history is often easier with an incremental load approach since all data from upstream sources can be retained in the target storage system as distinct versions or releases without duplicating the full datasets.
When using Incremental Data storage, potential challenges can arise, like incompatibility issues that may occur when new records invalidate existing data due to incompatible formats or types of data being added. This can create a bottleneck as the end user needs to get consistent and reliable insights from these corrupted data. Additionally, distributed systems used for processing incoming data could result in changes or deletions occurring in a different sequence (out-of-order events) than when it was received originally.
Data Storage Undelying Activities
Storage underlying activities are important since storage is a critical stage for all data journey activities. Therefore, data engineers should tackle these activities carefully:
-
Security: Although security is often perceived as a hindrance to the work of data engineers, they must recognize that security is, in fact, a vital enabler. By implementing robust security measures (encryption, anonymization…) for data at rest and in motion and fine-grained data access control, data engineers can enable wider data sharing and consumption within a company, leading to a significant increase in data value. The principle of least privilege should always be the rule, meaning that data access should only be granted proportionally to those who require it. Consequently, most data engineers don’t typically need full database access.
-
Data management is critical as we read and write data with storage systems. Having robust metadata enhances the quality of data. Cataloging the metadata enables data scientists, analysts, and ML engineers to discover and utilize the data efficiently. Data lineage, which traces the path of data, can speed up the process of identifying and solving data issues, allowing consumers to locate the raw sources upstream. You can also enable data versioning, which helps track the history of datasets, and with error recovery when processes fail, and data becomes corrupted. Note that GDPR and other privacy regulations have significantly influenced storage system design. Data that contains sensitive information requires a specific lifecycle management strategy. Data engineers must be prepared to respond to data deletion requests and selectively remove data as necessary to comply with privacy regulations.
-
DataOps’s primary concern is the operational monitoring of storage systems and the data itself. Monitoring Data has become bosom with data quality and metadata, representing an overlapping area with data management. In fact, data professionals (data engineers, data platform engineers…) must monitor storage infrastructure, the storage cost (FinOps), and data access. In addition, monitoring data itself implies actively seeking to understand its characteristics and watching for major changes (through data statistics, data profiling, and anomaly detection…).
-
Orchestration and storage are closely intertwined. Storage facilitates data flow through pipelines, while orchestration acts as the pump that drives data movement. Orchestration plays a critical role in managing the complexity of data systems by enabling engineers to combine multiple storage systems and query engines.
-
Data architecture: as I highlighted in Data 101 - part 3, about what makes a good data architecture, I explained that a good data architecture should primarily serve business requirements with a widely reusable set of building blocks while preserving well-defined best practices (principles) and making appropriate trade-offs. When designing a storage system for your data journey, you must be aware of your business constraints, challenges, and how your data initiative will evolve. You can assess your architecture against the six pillars of AWS Well-Architected Framework (WAF):
- Operational excellence: You should define, capture, and analyze storage metrics to gain visibility and take the appropriate actions. You must prepare and validate procedures for responding to events to minimize storage disruption and avoid data loss.
- Security: You must take the necessary actions to classify your data, protect it from leaks, and restrict its access to only relevant users.
- Reliability: you should define the necessary processes to back-up data and to meet your pre-defined requirements and SLA about the recovery time objectives (RTO) and recovery point objectives (RPO).
- Performance efficiency: You must choose your storage solution based on the required access method (block, file, or object), patterns of access (random or sequential), required throughput, frequency of access (online, offline, archival), frequency of update (WORM, dynamic), and availability and durability constraints.
- Cost optimization: You should monitor and manage storage usage and costs and Implement change control and resource management from project inception to end-of-life. This ensures you shut down or terminate unused resources to reduce waste.
- Sustainability: To minimize the environmental impacts of running the system workloads, you must implement data management practices to reduce the provisioned storage required to support your workload and the resources required to use it. Understand your data, and use storage technologies and configurations that best support the business value of the data and how it’s used. Use storage lifecycles to delete data that’s no longer required.
Summary
This post presented the different abstraction levels that form storage in a data journey. First, I discussed raw storage supports, systems, and other features that make storage more resilient and performant. Next, I illustrated the technologies used to store data and how data can be retained and used without turning the storage area into an unmanageable “data swamp.” For this, I overviewed the evolution of storage technologies from the 80’s of the last century to the last few years.
Finally, I highlighted that the most critical task for any data engineer is understanding the data to be retained, predicting access methods and patterns, and performing a sizing evaluation to know the required throughput, frequency of access, and updates of this data. These elements are necessary when you choose reliable and efficient storage.
References
- Reis, J. and Housley, M. Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media (2022).
- “Incremental Data Load vs Full Load ETL: 4 Critical Differences”, Sanchit Agarwal (Hevo)
- “Productionizing Machine Learning with Delta Lake”, Brenner Heintz and Denny Lee (Databricks Engineering Blog)
- “Data Lake Governance Best Practices”, Parth Patel, Greg Wood, and Adam Diaz (DZone).
- “File storage, block storage, or object storage?”, Redhat Blog
- “From Raw to Refined: The Staging Areas of Your Data Lake (Part 1)”, Bertrand Cariou (Trifacta Blog)
- “The Four Essential Zones of a Healthcare Data Lake”, Bryan Hinton