As I explained in the last posts, data architecture is a pivotal component of any data strategy. So, unsurprisingly, choosing the right data architecture should be a top priority for many organizations.
Data architectures can be classified based on data velocity. The two most popular velocity-based architectures are Lambda and Kappa. Data architectures can also be classified based on their operational mode or topology. Data Fabric, Data Hub, and Data Mesh are the three main architectures we’ll discuss in this classification.
In this post, I’ll dive deeply into the key features and characteristics of these architectures and provide a comparison to help you decide which is the best fit for your business needs. Whether you’re a data scientist, engineer, or business owner, this guide will provide valuable insights into the pros and cons of each architecture and help you make an informed decision on which one to choose.
What is Data Architecture?
Data architecture is part of enterprise architecture, inheriting its main properties: processes, strategy, change management, and evaluating trade-offs. According to TOGAF, Data Architecture is: “A description of the structure and interaction of the enterprise’s major types and sources of data, logical data assets, physical data assets, and data management resources.”
The DAMA DMBOOK defines data architecture as the process of “Identifying the data needs of the enterprise (regardless of structure) and designing and maintaining the master blueprints to meet those needs. Using master blueprints to guide data integration, control data assets, and align data investments with business strategy”.
Considering the preceding two definitions, we can define data architecture as the design of the blueprint for the organizational data assets, mapping out processes and tools to support the organization’s decision-making.
What makes a “Good” Data Architecture?
You know “good” when you see the worst. Bad data architecture is tightly coupled, rigid, overly centralized, and uses the wrong tools for the job, hampering development and change management. A good data architecture should primarily serve business requirements with a widely reusable set of building blocks while preserving well-defined best practices (principles) and making appropriate trade-offs. We borrow inspiration for “good” data architecture principles from several sources, especially the AWS Well-Architected Framework. It consists of six pillars:
- Operational excellence: Operations processes that keep a system running in production.
- Security: Protecting applications and data from threats.
- Reliability: The ability of a system to recover from failures and continue to function.
- Performance efficiency: A system’s ability to adapt to load changes.
- Cost optimization: Managing costs to maximize the value delivered.
- Sustainability: Minimizing the environmental impacts of running the system workloads.
In future articles, we will evaluate the data tools, solutions, and architectures regarding this set of principles.
Because data architecture is an abstract discipline, it helps to reason by categories of architecture. The following section outlines prominent examples and types of famous data architecture today. We classified in two different ways: By data Velocity and by Topology. Though this set of examples is not exhaustive, the intention is to expose you to some of the most common data architecture patterns and make an overview of the trade-off analysis needed when designing a good architecture for your use case.
Velocity-based data architectures
Data Velocity refers to how quickly data is generated and how quickly that data moves and can be processed into usable insights. Depending on the velocity of data they process, data architectures can be classified into two categories: Lambda and Kappa.
In this chapter, I describe the two architectures in more detail: their differences, the technologies we can use to realize them, and the tipping points that will make us decide to use one or the other.
1 - Lambda data architecture
The term “Lambda” is derived from lambda calculus (λ) which describes a function that runs in distributed computing on multiple nodes in parallel. Lambda data architecture was designed to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data and allows access to batch-processing and stream-processing methods in a hybrid way. It was developed in 2011 by Nathan Marz, the creator of Apache Storm, to solve the challenges of large-scale real-time data processing.
The Lambda architecture is an ideal architecture when you have a variety of workloads and velocities. It can handle large volumes of data and provide low-latency query results, making it suitable for real-time analytics applications like dashboards and reporting. In addition, this architecture is useful for batch processing (e.g., cleansing, transforming, or data aggregation), for stream processing tasks (e.g., event handling, machine learning models development, anomaly detection, or fraud prevention), and for building centralized repositories known as ‘data lakes’ to store structured/unstructured information.
The critical feature of Lambda architecture is that it uses two separate processing systems to handle different types of data processing workloads. The first is a batch processing system, which processes data in large batches and stores the results in a centralized data store (e.g., a data warehouse or a data lake). The second system is a stream processing system, which processes data in real-time as it arrives and stores the results in a distributed data store.
Lambda architecture solves the problem of computing arbitrary functions: evaluating the data processing function for any given input (in slow motion or in real-time). Furthermore, it provides fault tolerance by ensuring that the results from either system can be used as input into the other if one fails or becomes unavailable. The efficiency of this architecture becomes evident in the form of high throughput, low latency, and near-real-time applications.
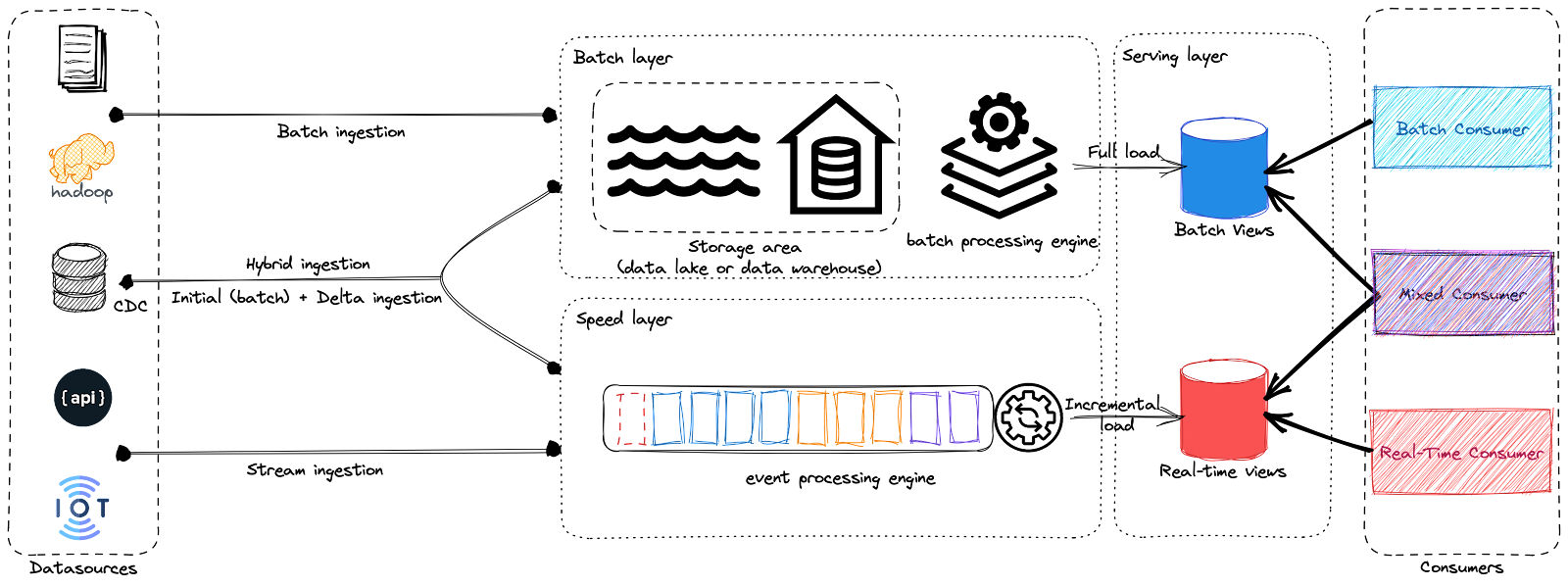
In the diagram above, you can see the main components of Lambda Architecture. It consists of the ingestion layer, the batch layer, the speed layer (or stream layer), and the serving layer.
- Batch Layer: The batch processing layer is designed to handle large volumes of historical data and store the results in a centralized data store, such as a data warehouse or distributed file system. This layer uses frameworks like Hadoop or Spark for efficient information processing, allowing it to provide an overall view of all available data.
- Speed Layer: The speed layer is designed to handle high-velocity data streams and provide up-to-date information views using event processing engines, such as Apache Flink or Apache Storm. This layer processes incoming real-time data and stores the results in a distributed data store such as a message queue or a NoSQL database.
- Serving Layer: The serving layer of Lambda architecture is essential for providing users with consistent and seamless access to data, regardless of the underlying processing system. Furthermore, it plays an important role in enabling real-time applications like dashboards and analytics that need rapid access to current information.
While Lambda architectures offer many advantages, such as scalability, fault-tolerance, and flexibility to handle a wide range of data processing workloads (batches and streams), it also comes with drawbacks that organizations must consider before deciding whether to use or not. In fact, Lambda architecture is a complex system that uses multiple technology stacks to process and store data. In addition, the underlying logic is duplicated in the Batch and the Speed Layers for every stage. It can be challenging to set up and maintain, especially for organizations having limited resources. Furthermore, this duplication has a cost: data discrepancy as although having the same logic, the implementation is different from one layer to another. Thus, the error/bug probability is definitively higher, and you may encounter different results from batch and speed layers.
2 - Kappa data architecture
In 2014, when he was still working at LinkedIn, Jay Kreps started a discussion where he pointed out some drawbacks of the Lambda architecture. This discussion further led the big data community to another alternative that used fewer code resources.
The principal idea behind this is that a single technology stack can be used for both real-time and batch data processing. This architecture was called Kappa. Kappa architecture is named after the Greek letter “Kappa” (ϰ), which is used in mathematics to represent a “loop” or “cycle.” The name reflects the architecture’s emphasis on continuous data processing or reprocessing rather than a batch-based approach. At its core, it relies on streaming architecture: incoming data is first stored in an event streaming log, then processed continuously by a stream processing engine, like Kafka, either in real-time or ingested into any other analytics database or business application using various communication paradigms such as real-time, near real-time, batch, micro-batch, and request-response.
Kappa architecture is designed to provide a scalable, fault-tolerant, and flexible system for processing large amounts of data in real-time. The Kappa architecture is considered a simpler alternative to the Lambda architecture as it uses a single technology stack to handle both real-time and historical workloads, treating everything as streams. The primary motivation for inventing the Kappa architecture was to avoid maintaining two separate code bases (pipelines) for the batch and speed layers. This allows it to provide a more streamlined and simplified data processing pipeline while still providing fast and reliable access to query results.

The most important requirement for Kappa was Data reprocessing, making visible the effects of data changes on the results. Consequently, the Kappa architecture is composed of only two layers: the stream layer and the serving one.
In Kappa architecture, there is only one processing layer: the stream processing layer. This layer is responsible for collecting, processing, and storing live-streaming data. This approach eliminates the need for batch-processing systems by utilizing an advanced stream processing engine such as Apache Flink, Apache Storm, Apache Kafka, or Apache Kinesis to handle high volumes of data streams and provide fast, reliable access to query results. The stream processing layer is divided into two components: the ingestion component, which collects data from various sources, and the processing component, which processes this incoming data in real-time.
- Ingestion component: This layer collects incoming data from various sources, such as logs, database transactions, sensors, and APIs. The data is ingested in real-time and stored in a distributed data store, such as a message queue or a NoSQL database.
- Processing component: The Processing component of the Kappa architecture is responsible for handling high-volume data streams and providing fast and reliable access to query results. It utilizes event processing engines, such as Apache Flink or Apache Storm, to process incoming data in real-time and historical data coming from a storage area before storing it in a distributed data store.
Nowadays, real-time data beats slow data. That’s true for almost every use case. Nevertheless, Kappa Architecture cannot be taken as a substitute for Lambda architecture. On the contrary, it should be seen as an alternative to be used in those circumstances where the active performance of the batch layer is not necessary for meeting the standard quality of service.
While Kappa architectures come with the promises of scalability, fault-tolerance, and streamlined management (simpler to set up and maintain compared to Lambda), it also has disadvantages that organizations must consider carefully. Kappa architecture is theoretically simpler than Lambda but can still be technically complex for businesses unfamiliar with stream processing frameworks. However, the major drawback of Kappa, from my point of view, is the cost of infrastructure while scaling the event streaming platform. Storing high volumes of data in an event streaming platform can be costly and raise other scalability issues, especially when dealing with Terabytes or Petabytes. Moreover, the difference between event time and processing time can lead to late-arriving data, which can represent a big challenge for a Kappa architecture: need for watermarking, state management, reprocessing, backfill…
3 - Dataflow Model
Lambda and Kappa emerged as attempts to overcome the shortcomings of the Hadoop ecosystem in the 2010s by trying to integrate complex tools that were not inherently compatible. However, both approaches struggled to resolve the fundamental challenge of reconciling batch and streaming data. Despite this, Lambda and Kappa provided inspiration and a foundation for further advancements in pursuing a more unified solution.
Unifying multiple code paths is one of the most significant challenges when managing batch and stream processing. Even with the Kappa architecture’s unified queuing and storage layer, engineers still face the challenge of using different tools for collecting real-time statistics and running batch aggregation jobs. Today, engineers are working to address this challenge in various ways. For instance, Google has made significant progress by developing the Dataflow model and the Apache Beam framework, which implements this model.
 Windowing patterns.
Windowing patterns.
The fundamental concept behind the Dataflow model is to treat all data as events and perform aggregations over different types of windows. Real-time event streams are unbounded data, while data batches are bounded event streams that have natural windows. Engineers can choose from different windows, such as sliding or tumbling, for real-time aggregation. The Dataflow model enables real-time and batch processing to occur within the same system, using almost identical code. The idea of “batch as a special case of streaming” has become increasingly widespread, with frameworks like Flink and Spark adopting similar approaches.
4 - Architecture for IoT
The Internet of Things (IoT) is a network of physical devices, vehicles, appliances, and other objects (aka, things) embedded with sensors, software, and connectivity that enables them to collect and exchange data. These devices can be anything from smart home appliances to industrial machinery to medical devices, and they are all connected to the Internet. The data collected by IoT devices can be used for various purposes, such as monitoring and controlling devices remotely, optimizing processes, improving efficiency and productivity, and enabling new services and business models. IoT Data is generated from devices that collect data periodically or continuously from the surrounding environment and transmit it to a destination. IoT devices are often low-powered and operate in low-resource/low-bandwidth environments.
Although the concept of IoT devices dates back several decades, the widespread adoption of smartphones created a massive swarm of IoT devices almost overnight. Since then, various new categories of IoT devices have emerged, including smart thermostats, car entertainment systems, smart TVs, and smart speakers. The IoT can potentially revolutionize many industries, including healthcare, manufacturing, transportation, and energy. It has transitioned from a futuristic concept to a significant domain in data engineering. It is expected to become one of the primary ways data is generated and consumed.
Architectures for IoT are Event-Driven Architectures that encompass the ability to create, update, and asynchronously move events across various parts of the data journey. This workflow involves three main areas: event production, routing, and consumption. An event must be produced and routed to something that consumes it without tightly coupled dependencies among the producer, event router, and consumer.
An event producer is a device in this architecture, which isn’t beneficial unless you can get its data. So, an IoT gateway is a critical component that collects and securely routes device data to the appropriate destinations on the internet. From there, events and measurements can flow into an event ingestion architecture with all challenges it brings—e.g., late-arriving data, data structure and schema disparities, data corruption, and connection disruption.

Then storage requirements for an IoT system will vary greatly depending on the latency requirements of the IoT devices. For instance, if remote sensors are collecting scientific data that will be analyzed at a later time, batch object storage may be sufficient. Conversely, if a system backend constantly analyzes data in a home monitoring, or an automation solution, near real-time responses may be necessary. A message queue or time-series database would be more suitable in such cases. Preferably in-memory storage supports are essential for low latency.
Just like the Kappa architecture, the serving layer is a real-time view to providing users with consistent and seamless access to IoT data., It plays an important role in enabling real-time applications like dashboards and analytics that need rapid access to current information.
Topology-based data architectures
The debate between data architects has focused on the merits of the existing data ontologies. While data architectures can be grouped in relation to data velocity, as we’ve seen with Lambda and Kappa, another way to classify them is the data operational model or topology, which is technology-agnostic. Remember that three types of operating models can exist in any organization (Data 101 - part 2): centralized, decentralized, and hybrid.
In this chapter, I describe three topology-based data architectures in more detail: data fabric, data mesh, and data hub.
1 - Centralized Data Architectures: Data Hub
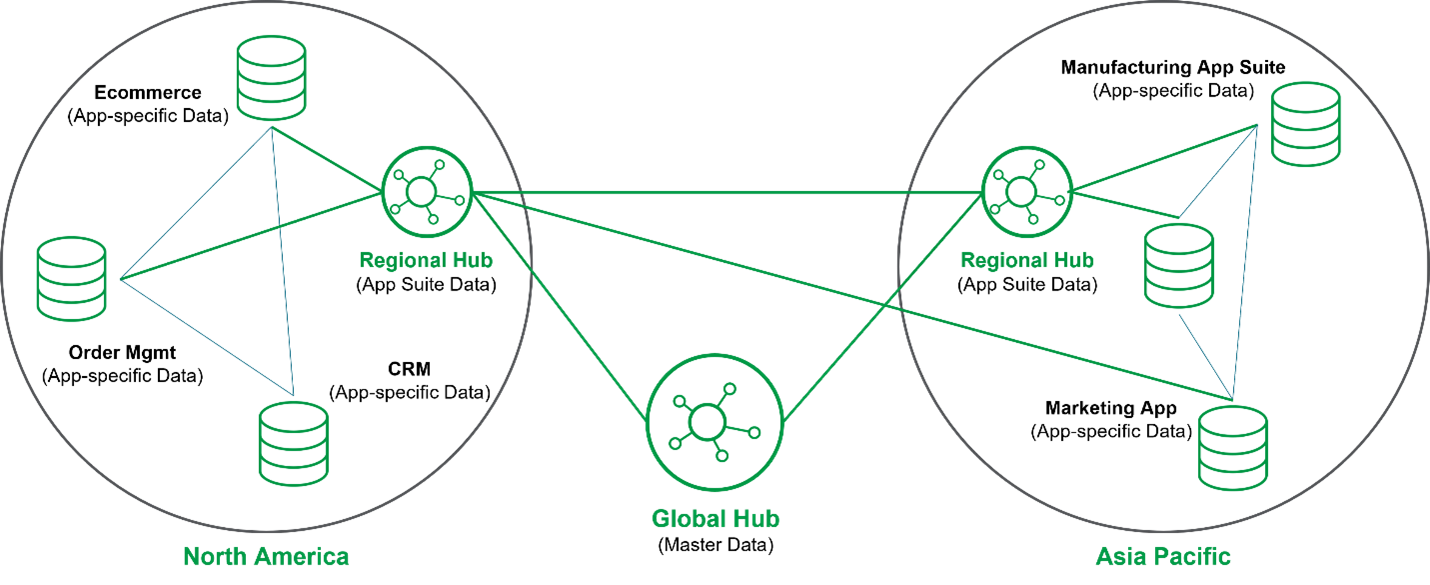
A data hub is an architecture for managing data in a centralized way. It can be described as a data exchange with frictionless data flow at its core. It acts as a central repository of information with connections to other systems and customers, allowing data sharing between them. Endpoints interact with the Data Hub by providing data into it or receiving data from it, and the hub provides a mediation and management point, making visible how data flows across the enterprise. A data hub architecture facilitates this exchange by connecting producers and consumers of data together. The seminal work behind data hub architecture was a Gartner research paper published in 2017. In this paper, Gartner suggested a technology-neutral architecture for connecting data producers and consumers, which was more advantageous than point-to-point alternatives. Subsequent research further developed this concept, resulting in the current definition of a data hub’s attributes.
 Data hub attributes.
Data hub attributes.
The hub is structured and consumed according to the models defined by its users. Governance policies are established to ensure data privacy, access control, security, retention, and disposal of information securely. Integration strategies such as APIs or ETL processes can be used for working with the data stored within the hub. Persistence defines which type of database should be utilized for storing this data (e.g., relational databases). The implementation of a Data Hub architecture is a facilitator for:
- Consolidating and streamlining the most commonly used data into a central point,
- Establishing an effective data control system to improve data quality,
- Ensuring traceability on flows and offering statistical monitoring of the company’s activity,
- Improving knowledge of the exchanged data,
- Gradually building the company data model.
 Data hub.
Data hub.
Gartner proposed that specialized, purpose-built data hubs could be used for various purposes. These included analytics data hubs used for collecting and sharing information for downstream analytics processes; application data hubs used as domain context for specific applications or suites; integration data hubs designed to facilitate the sharing of data through different integration styles; master data hubs focused on distributing master data across enterprise operational systems and procedures; and finally, reference data hubs with similar goals but limited in scope to “reference” (e.g., commonly utilized codes).
Data centralization implemented in data hubs ensures that data is managed from a central source but is designed to make the data accessible from many different points. It serves to minimize data silos, foster collaboration, and provide visibility into emerging trends and impacts across the enterprise. A centralized data view helps align data strategy with business strategy by delivering a 360° view of trends, insights, and predictions so that everyone in the organization can move in the same direction.
The challenge with data centralization is that processes can be slow without accelerators or some sort of self-service strategy in place. As a result, requests take longer and longer to get done. The business can’t move forward fast enough, and opportunities for better customer experiences and improved revenue are lost simply because they can’t be achieved quickly.
For these reasons, Gartner has recently updated the data hub concept to allow organizations to run multiple hubs in an interconnected way. This way, the data hub could take advantage of data centralization and leverage decentralization by putting more responsibility and power back into the lines of business.
The most common usage of Data hubs is Data Warehouses. A data warehouse is a central data hub used for reporting and analysis. Data in a data warehouse is typically highly formatted and structured for analytics use cases. As a result, it’s among the oldest and most well-established data architectures. In 1989, Bill Inmon originated the notion of the data warehouse, which he described as “a subject-oriented, integrated, nonvolatile, and time-variant collection of data in support of management’s decisions.” Though technical aspects of the data warehouse have evolved significantly, we feel this original definition still holds its weight today.
Traditionally, a data warehouse pulls data from application systems by using ETL. The extract phase pulls data from source systems. Finally, the transformation phase cleans and standardizes data, organizing and imposing business logic in a highly modeled form. We will release a dedicated blog post on data modeling.
One variation on ETL is ELT. With the ELT mode in data warehouse architectures, data gets moved more or less directly from production systems into a staging area in the data warehouse. Staging in this setting indicates that the data is in a raw form. Rather than using an external system, transformations are handled directly in the data warehouse. Data is processed in batches, and transformed output is written into tables and views for analytics.

During the era of big data, the data lake emerged as another widely used centralized architecture. The idea was to create a central repository where all types of structured and unstructured data could be stored without any strict structural constraints. The data lake was intended to empower businesses by providing unlimited data supply. The initial version of the data lake, known as “data lake 1.0,” started with distributed systems like Hadoop (HDFS). As the cloud grew in popularity, these data lakes moved to cloud-based object storage, with extremely cheap storage costs and virtually limitless storage capacity. Instead of relying on a monolithic data warehouse where storage and compute are tightly coupled, the data lake stores an immense amount of data of any size and type.
 Data Lake 1.0.
Data Lake 1.0.
Despite the hype and potential benefits, the first generation of data lakes - data lake 1.0 - had several significant drawbacks. The data lake essentially turned into a dumping ground, creating terms such as data swamp and dark data, as many data projects failed to live up to their initial promise. Managing data became increasingly difficult as the volume of data grew exponentially, and schema management, data cataloging, and discovery tools were lacking. In addition, the original data lake concept was essentially write-only, creating huge headaches with the arrival of regulations such as GDPR that required targeted deletion of user records. Processing data was also a major challenge, with relatively basic data transformations, such as joins, requiring the implementation of complex MapReduce jobs.
Various players have sought to enhance the concept to fully realize its promise in response to the limitations of first-generation data lakes. For example, Databricks introduced the notion of a data lakehouse. The lakehouse incorporates the controls, data management, and data structures found in a data warehouse while still housing data in object storage and supporting a variety of query and transformation engines. In particular, the data lakehouse supports atomicity, consistency, isolation, and durability (ACID) transactions. It is a significant disruption from the original data lake, where you simply pour in data and never update or delete it. The term data lakehouse suggests a convergence between data lakes and data warehouses.
 Data Lake + Data Warehouse = Data Lakehouse.
Data Lake + Data Warehouse = Data Lakehouse.
2 - Decentralized Data Architectures: Data Fabric
Data decentralization is a data management approach that eliminates the need for a central repository by distributing data storage, cleaning, optimization, output, and consumption across different organizational departments. This helps reduce complexity when dealing with large amounts of data and issues such as changing schema, downtime, upgrades, and backward compatibility.
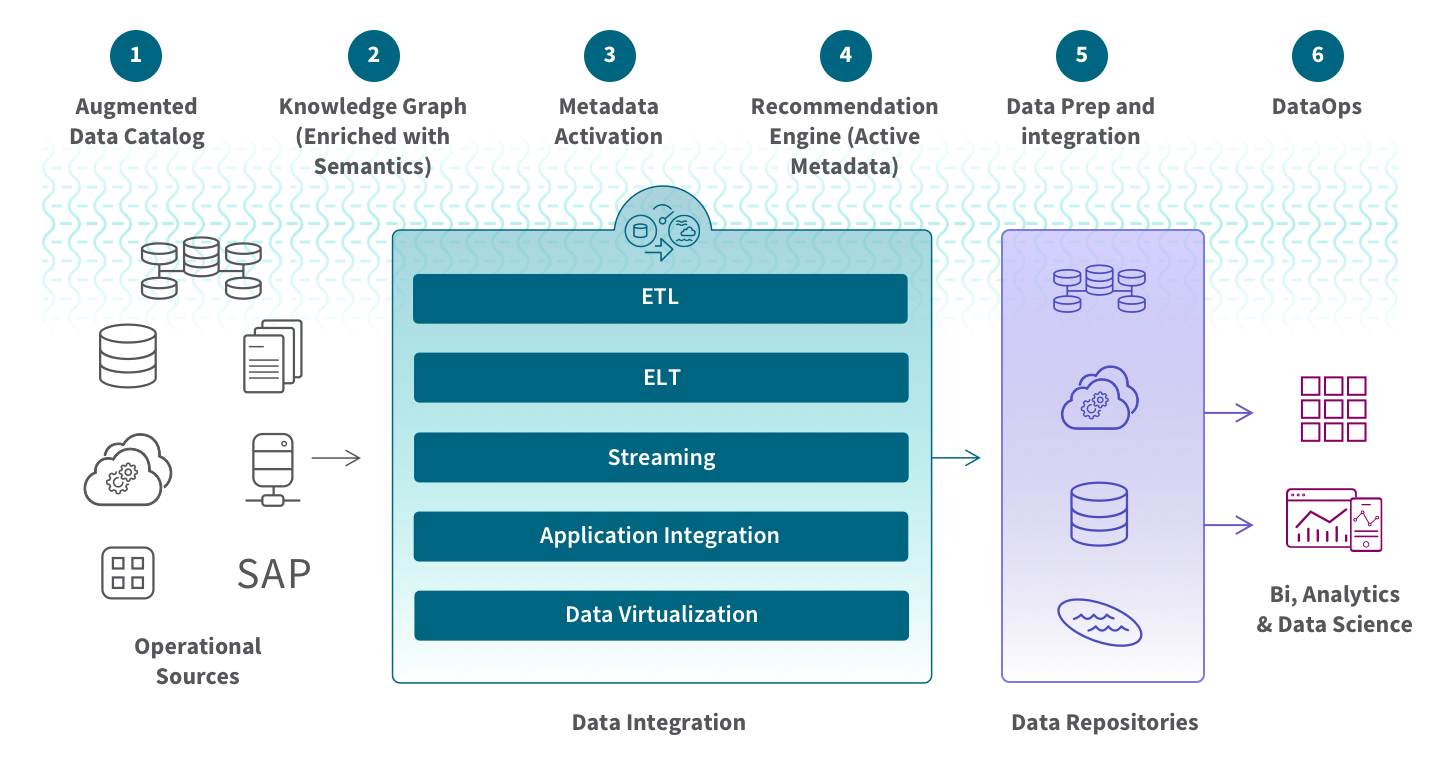
Data fabric was created first as a distributed data environment that enables the ingestion, transformation, management, storage, and access of data from various repositories for use cases such as business intelligence (BI) tools or operational applications. It provides an interconnected web-like layer to integrate data-related processes by leveraging continuous analytics over current and inferred metadata assets. It utilizes advanced techniques like active metadata management, semantic knowledge graphs, and embedded machine learning/AutoML capabilities to maximize efficiency.
This concept was coined first in late 2016 by Noel Yuhanna of Forrester Research in his publication “Forrester Wave: Big Data Fabric.” His paper described a technology-oriented approach combining disparate data sources into one unified platform using Hadoop and Apache Spark for processing. The goal is to increase agility by creating an automated semantic layer that accelerates the delivery of insights while minimizing complexity with streamlined pipelines for ingestion, integration, and curation.
Over the years, Noel has developed his Big Data Fabric concept further. His current vision for this fabric is to provide solutions that meet various business needs, such as creating an all-encompassing view of customers, customer intelligence, and analytics related to the Internet of Things. The data fabric includes components like AI/ML, data catalog, data transformation, data preparation, data modeling, and data discovery. It also provides governance and modeling capabilities that enable complete end-to-end data management.
Gartner has also adopted the term “data fabric” and defined it similarly: they describe it as an emerging data management and integration design that enables flexible, reusable, and enhanced data integration pipelines, services, and semantics to support various operational or analytics use cases across multiple deployment platforms. Data fabrics combine different data integration techniques while utilizing active metadata, knowledge graphs, semantics, and machine learning (ML) to improve their design process. They define five inner attributes as parts of the data fabric:
 Data fabric attributes.
Data fabric attributes.
In a fabric, active metadata contains catalogs of passive data elements such as schemas, field types, data values, and knowledge graph relationships. The knowledge graph stores and visualizes the complex relationships between multiple data entities. It maintains data ontologies to help non-technical users to interpret data.
The data fabric leverage AI and Machine Learning capabilities to automatically assist and enhance data management activities. This architecture should also offer integration capabilities to dynamically ingest disparate data into the fabric where it is stored, analyzed, and accessed. Furthermore, automated data orchestration supports a variety of data and analytics use cases across the enterprise. It allows users to apply DataOps principles throughout the process for agile, reliable, and repeatable data pipelines.
Data fabric is a technology-agnostic architecture. However, its implementation enables you to scale your Big Data operations for both batch processes and real-time streaming, providing consistent capabilities across cloud, hybrid multi-cloud, on-premises, and edge devices. It simplifies the flow of information between different environments so that a complete set of up-to-date data is available for analytics applications or business processes. Additionally, it reduces time and cost by offering pre-configured components and connectors, eliminating the need to manually code each connection.
3 - Decentralized Data Architectures: Data Mesh
Data mesh was introduced in 2019 by Zhamak Dehghani. In her blog post, she argued that a decentralized architecture was necessary due to the shortcomings of centralized data warehouses and lakes.
A data mesh is a framework that enables business domains to own and operate their domain-specific data without the need for a centralized intermediary. It draws from distributed computing principles, where software components are shared among multiple computers running together as a system. In this way, data ownership is spread across different business domains, each responsible for creating its own products. Additionally, it allows easier contextualization of the collected information to generate deeper insights while simultaneously facilitating collaboration between domain owners to create tailored solutions according to specific needs.
In a subsequent article, Zhamak revised her position by proposing four principles that form this new paradigm.
 Data mesh principles.
Data mesh principles.
- Domain-oriented: Data mesh is based on decentralizing and distributing responsibility for analytical data, its metadata, and the computation necessary to serve it to people closest to the data. This allows for continuous change and scalability in an organization’s data ecosystem. To do this, Data Mesh decomposes components along organizational units or business domains that localize changes or evolution within that bounded context. By doing so, ownership of these components can be distributed across stakeholders close to the data.

- Data-as-a-product: One of the issues with existing analytical data architectures is that it can be difficult and expensive to discover, understand, trust, and use quality data. If not appropriately addressed, this problem will only become worse as more teams provide data (domains) in a decentralized manner, which would violate the first principle. To address these challenges related to data quality and silos, a data mesh must treat analytical data provided by domains as a product and the consumers of that product as customers. The product will become the new unit of architecture that should be built, deployed, and maintained as a single quantum. It ensures that data consumers can easily discover, understand, and securely use high-quality data across many domains.

- Self-service data infrastructure: The infrastructure platform allows domain teams to autonomously create and consume data products without worrying about the underlying complexity of the building, executing, and maintaining secure and interoperable solutions.
A self-service infrastructure should provide a streamlined experience that enables data domain owners to focus on their core objectives instead of worrying about technical details. The self-serve platform capabilities fall into multiple categories or planes:
- Infrastructure provisioning plane that supports the provisioning of the underlying infrastructure required to run the components of a data product and the mesh of products.
- Product developer experience plane is the main interface that a data product developer uses. It simplifies and abstracts many of the complexities associated with supporting their workflow, providing an easier-to-use higher level of abstraction than what’s available through the Provisioning Plane.
- Mesh supervision plane provides a way to manage and supervise the entire data product mesh, allowing global control over all connected products. This includes features such as quality monitoring, performance, security protocols assessment, providing access control mechanisms, and more. Having these capabilities at the mesh level rather than individual product levels allows for greater flexibility in managing large networks of interconnected data products.
- Federated governance: data mesh implementation requires a governance model that supports decentralization and domain self-sovereignty, interoperability through a dynamic topology, and automated execution of decisions by the platform. Integrating global governance and interoperability standards into the mesh ecosystem allows data consumers to gain value from combining and comparing different data products within the same system.
The data mesh combines these principles into a unified, decentralized, and distributed system, where data product owners have access to shared infrastructure that is self-service enabled for the development of pipelines that share data in an open yet governed manner. This allows them to develop products quickly without sacrificing governance or control over their domain’s data assets.

The data mesh differs from the traditional approach of managing the pipelines and data as separate entities with shared storage infrastructure. Instead, it views all components (i.e., pipelines, data, and storage infrastructure) at the granularity of a bounded context within a given domain to create an integrated product. This allows for greater flexibility in terms of scalability and customization while providing better visibility into how different parts interact.
Summary
The data market is often seen as being stagnant and mature, but the current discussion on data architecture proves this to be a wrong statement.
Data types are increasing in number, usage patterns have grown significantly, and a renewed emphasis has been placed on building pipelines with Lambda and Kappa architectures in the form of data hubs or fabrics. Either grouped by velocity or the kind of topology they provide, data architectures are not orthogonal. The data architectures and paradigms we presented in this post can be used side-by-side, used alternately when there is a need to alternate between them. In addition, of course, they can be mixed in architectures like data mesh, in which each data product is a standalone artifact. We can imagine that a Lambda architecture is implemented in some data products and Kappa architectures in others.
Despite all of these changes, however, it’s clear that the debate over how best to structure our approach to handling data is far from over - we’re just getting started!
References
- Akidau T. et al., The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Proceedings of the VLDB Endowment, vol. 8 (2015), pp. 1792-1803.
- Reis, J. and Housley M. Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media (2022).
- “Lambda vs. Kappa Architecture. A Guide to Choosing the Right Data Processing Architecture for Your Needs”, Dorota Owczarek.
- “A brief introduction to two data processing architectures — Lambda and Kappa for Big Data”, Iman Samizadeh, Ph.D.
- “What Is Lambda Architecture?”, Hazelcast Glosary.
- “What Is the Kappa Architecture?”, Hazelcast Glosary.
- “Kappa Architecture is Mainstream Replacing Lambda”, Kai Waehner.
- “Data processing architectures – Lambda and Kappa”, Julien Forgeat.
- “Why the Data Hub Architecture?”, Stambia Solutions.
- “Data Hub, Fabric or Mesh? Part 1 of 2”, Clive Bearman.
- “Data Hub, Fabric or Mesh? Part 2 of 2”, Clive Bearman.
- “What Is Data Fabric?”, Qlik.
- “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”, Zhamak Dehghani (Martin Fowler Blog).
- “Data Mesh Principles and Logical Architecture”, Zhamak Dehghani (Martin Fowler Blog).